@[toc]
一、二叉堆和优先队列
队列有一种变体称为优先队列Priority Queue。优先队列的出队跟队列一样从队首出队,但在优先队列内部,数据项的次序却是由“优先级”来确定:

@[toc]
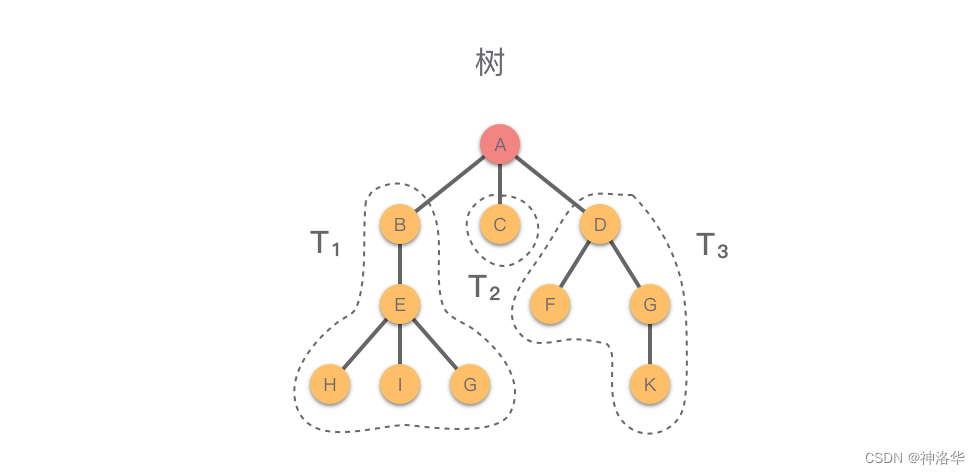
树(Tree):由 $n \ge 0$ 个节点与节点之间的边组成的有限集合。当 $n = 0$ 时称为空树,当 $n > 0$ 时称为非空树。
树由若干节点,以及两两连接节点的边组成,并具有以下性质:
之所以把这种数据结构称为「树」是因为这种数据结构看起来就像是一棵倒挂的树,也就是说数据结构中的「树」是根朝上,而叶朝下的。如下图所示。
@[toc]
一、 动态规划基础知识
1.1 动态规划简介
动态规划(Dynamic Programming):简称 DP,是一种通过把原问题分解为相对简单的子问题的方式而求解复杂问题的方法。
动态规划方法与分治算法类似,却又不同于分治算法。
「动态规划的核心思想」是:
@[toc]
参考:
- 【资料】算法通关手册、背包九讲 - 崔添翼
- 【文章】背包 DP - OI Wiki
- 【B站视频】代码随想录详解0-1背包
背包问题:背包问题是线性 DP 问题中一类经典而又特殊的模型。背包问题可以描述为:给定一组物品,每种物品都有自己的重量、价格以及数量。再给定一个最多能装重量为 $W$ 的背包。现在选择将一些物品放入背包中,请问在总重量不超过背包载重上限的情况下,能装入背包的最大价值总和是多少?

@[toc]
参考
- 《算法通关手册》-哈希表篇
- 【博文】散列表(上)- 数据结构与算法之美 - 极客时间
一、哈希表
1.1 哈希表简介
哈希表(Hash Table):也叫做散列表。是根据关键码值(Key Value)直接进行访问的数据结构。
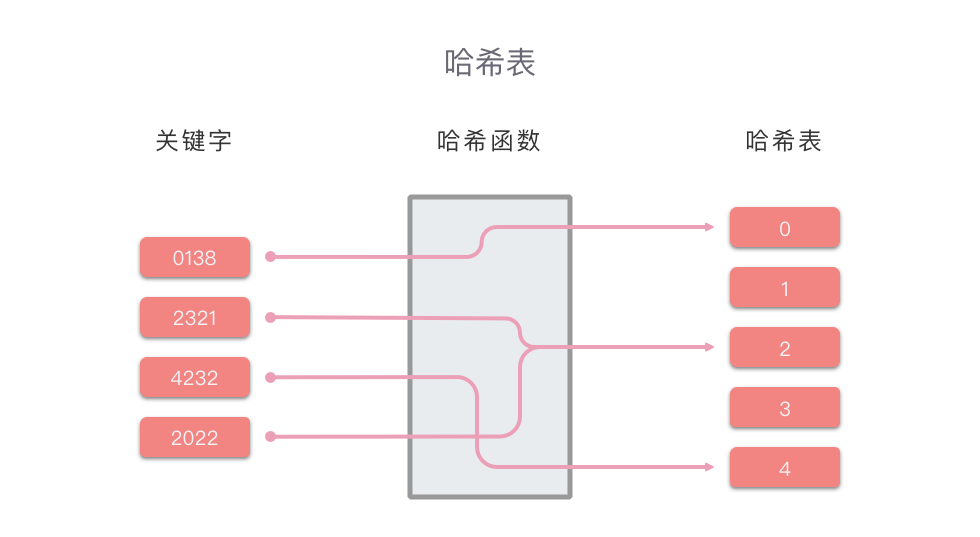
哈希表通过「键 key 」和「映射函数 Hash(key) 」计算出对应的「值 value」,把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做「哈希函数(散列函数)」,存放记录的数组叫做「哈希表(散列表)」。
哈希表的关键思想是使用哈希函数,将键 key 映射到对应表的某个区块中。我们可以将算法思想分为两个部分:
哈希表的原理示例图如下所示:
@[toc]
本文主要参考《算法通关手册》堆栈篇
一、 堆栈基础知识
1.1 简介
堆栈(Stack):简称为栈。一种线性表数据结构,是一种只允许在表的一端进行插入和删除操作的线性表。
我们把栈中允许插入和删除的一端称为 「栈顶(top)」;另一端则称为 「栈底(bottom)」。当表中没有任何数据元素时,称之为 「空栈」。
堆栈有两种基本操作:「插入操作」 和 「删除操作」。

@[toc]
本文主要参考《算法通关手册》链表篇
一、链表基础
1.1 无序表(UnorderedList)
链表(Linked List):一种线性表数据结构。它使用一组任意的存储单元(可以是连续的,也可以是不连续的),来存储一组具有相同类型的数据。简单来说,「链表」 是实现线性表链式存储结构的基础。
虽然列表数据结构要求保持数据项的前后相对位置,但这种前后位置的保持,并不要求数据项依次存放在连续的存储空间。如下图,数据项存放位置并没有规则,但如果在数据项之间建立链接指向,就可以保持其前后相对位置。第一个和最后一个数据项需要显示标记出来,一个是队首,一个是队尾,后面再无数据了。

@[toc]
排序
冒泡排序(Bubble Sort)基本思想:通过相邻元素之间的比较与交换,使值较小的元素逐步从后面移到前面,值较大的元素从前面移到后面。这个过程就像水底的气泡一样向上冒,这也是冒泡排序法名字的由来。
动画演示:
@[toc]
参考代码随想录《数组理论基础》
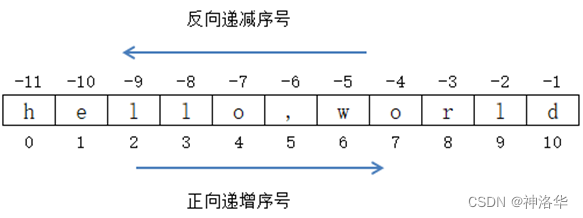
数组是存放在连续内存空间上的相同类型数据的集合,数组可以方便的通过下标索引的方式获取到下标下对应的数据,例如:
有两点需要注意:
- 数组下标都是从0开始的。
- 数组内存空间的地址是连续的