
一些说明
比赛官方链接为:《零基础入门NLP - 新闻文本分类》。
讨论区有大佬张帆、惊鹊和张贤等人的代码,值得大家仔细阅读。
最后我的模型参考了这些代码的一些config,比如bert.config,lr等等。然后大佬们的代码对我来说还是太复杂,pytorch功力不够,看的吃力。所以自己用huggingface实现了。
第一步分词我就考虑了很久,没有像张帆他们那样用pytorch具体一步步写,而是参考HF主页的教程。所以一开始我是翻译了构建tokenizer的教程,如果对比赛代码中分词有疑问的可以参考。
三、最终代码及解析
主要思路:
- 构建分词器。参考HF教程《How to train and use your very own tokenizer》。3750、648、900这三个应该是标点符号(详见张帆task02的分析),直接把这三个替换成‘,’、‘.’和‘!’。主要是为了断句。在预分词器pre_tokenizers.BertPreTokenizer中,有根据标点进行断句的方法,直接将文本换成带标点的格式就行,预分词器会自动断句。
- 和BERT 有关的 Tokenizer 主要写在models/bert/tokenization_bert.py中。这部分内容其实在nlp教程3.1里面有写。
- BasicTokenizer负责处理的第一步——按标点、空格等分割句子,并处理是否统一小写,以及清理非法字符。对于中文字符,通过预处理(加空格)来按字分割;同时可以通过never_split指定对某些词不进行分割;
- 分词器参考bert-baseChinese的分词器配置tokenizer.json。具体的:
- “normalizer”:”BertNormalizer”。
- “pre_tokenizer”:{“type”:”BertPreTokenizer”}
- “post_processor”:{“type”:”TemplateProcessing”}
- “decoder”:{“type”:”WordPiece”,”prefix”:”##”,”cleanup”:true}
- “model”:{“type”:”WordPiece”,”unk_token”:”[UNK]”…}
- 词表大小选的7000,我是看讨论区是6900+,这里还有点没想清楚。中文的wordpiece是也可以吧高频率的汉字拼成词语吧,用‘##’连接。如果这样,采用wordpiece,vocab size大一点,最后整词掩码感觉效果会更好。但是整词掩码我不知道怎么写,所以最后没有用。没有整词掩码,就没有wordpiece的必要了。所以我做的有点矛盾,最后是懒得改了,就这么写。
- 预训练bert模型。参考nlp教程4.5 《微调语言模型》。用BertConfig配置模型参数,设置了一个小型的初始化bert进行mlm任务预训练。
- 训练集选择train_set和test两个csv,因为test预训练时不需要分类标签,只作为掩码任务,不存在数据泄露问题。注意训练数据要把三个token换成标点。
- 最终我训练了8个epoch(第一次5个epoch,lr=4e-4,loss=1.695,batch_size=128。第二次3个epoch,lr=2e-4,结果一开始steps=3000时,loss=1.78,应该是第二次训练的lr还是太大,震荡了。第二个epoch快训练完才降到1.69,浪费了两个小时。最终loss是1.63)
- 我选择的是colab的tpu进行训练,每个epoch是13903steps,大概50-60分钟左右。如果是colab-GPU,大概31-35小时。colab tpu使用可以参考我的代码。如果选择tpu时提示无法分配,不用管,继续连接,第二次连接我都成功了。
- 分类微调,加一个首尾截断。我是之前看文章说文章分类首尾截断效果更好(论文解读】文本分类上分利器:Bert微调trick大全)。trainer没有首尾截断的机制,在前面数据处理时用pandas实现。最终训练了6个epoch,用tpu大概88分钟(我也是跑了两次。中间colab断了…)
- 读取测试集,跟训练集一样处理,保存结果并提交。最终得分0.961。
class BertTokenizer(PreTrainedTokenizer):
...
...
if do_basic_tokenize:
self.basic_tokenizer = BasicTokenizer(
do_lower_case=do_lower_case,
never_split=never_split,
tokenize_chinese_chars=tokenize_chinese_chars,
strip_accents=strip_accents,
)
self.wordpiece_tokenizer = WordpieceTokenizer(vocab=self.vocab, unk_token=self.unk_token)
...
...
class BasicTokenizer(object):
...
...
#BasicTokenizer中定义了标点分割的方法,不需要再去另外处理
def _run_split_on_punc(self, text, never_split=None):
"""Splits punctuation on a piece of text."""
if never_split is not None and text in never_split:
return [text]
chars = list(text)
i = 0
start_new_word = True
output = []
while i < len(chars):
char = chars[i]
if _is_punctuation(char):
output.append([char])
start_new_word = True
else:
if start_new_word:
output.append([])
start_new_word = False
output[-1].append(char)
i += 1
return ["".join(x) for x in output]
3.1 构建分词器
参考本文第二节,并查看了bert-base-chinese,josn文件配置分词器。训练语言模型参考此教程及中文翻译。
感受:最坑的是训练分词器,从头到尾选择decoders, models, pre_tokenizers, processors, trainers, Tokenizer有点麻烦。最后装进PreTrainedTokenizerFast之后还有些东西需要设置,看了好多次文档才试出来。#从google云盘上加载数据
from google.colab import drive
drive.mount('/content/drive')
import os
os.chdir('/content/drive/MyDrive/transformers/天池-入门NLP - 新闻文本分类')
#安装transformers=4.11.2 |
#将3750/648/900改成标点符号,删除原text列,新增words列重名为text列 |
#构建数据批处理迭代器,这部分代码是参考HF主页教程 |
#设置分词器并进行训练 |
#进行分词后处理 |
#测试分词结果 |
"""保存模型并重新加载 |
3.2 预训练bert模型
参考nlp教程4.5#data_collator是一个函数,负责获取样本并将它们批处理成张量
#在data_collator中可以确保每次以新的方式完成随机掩蔽。
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(tokenizer=fast_tokenizer,mlm=True,mlm_probability=0.15)
#初始化bert模型,参数参考讨论区代码 |
#数据进行分词预处理,删除‘text'列,否则后面拼接的时候会报错。 |
# 拼接所有文本,这一块解释可以看nlp 4.5教程 |
#加载和保存拼接后的文本,掉线的时候这么做 |
#解码分词器预处理的lm_datasets数据,里面有标点符号 |
#使用GPU训练,运行这段代码 |
==GPU memory开始占用1GB,但是还没开始使用计算。==
#安装TPU依赖 |
#设定args和trainer准备训练.3000步看一次loss,9000步保存一次模型(怕掉线) |
#训练并保存模型 |
这段是当时batch_size太高,显存爆了,我找一下原因。可以忽略。
1%的数据试验
- 第一次训练涨到5.9GB,5个epoch,540steps,batch_size=128。训练完后是显存1.2GB。logging_steps=100,可以选择多久看一次loss。
- 再次训练没有指定batch_size,显存是1.8GB。训练完1.5GB。算了一下默认batch_size=8。
3.3 分类任务微调:
- 加载预训练好的模型,GPU或TPU训练
from transformers import AutoModelForSequenceClassification
model=AutoModelForSequenceClassification.from_pretrained("./pre_Bert",num_labels=14)
#使用GPU训练
import torch
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
model.to(device)
#将模型复制到TPU进行训练
import torch_xla.core.xla_model as xm
device = xm.xla_device()
model.to(device) - 读取数据集,准备进行预处理
from datasets import Dataset |
- 划分训练集和测试集,比例0.1
val_df=train_df.iloc[:20000, ]
trains_df=train_df.iloc[20000:, ]
#首尾截断
val_df['summary']=val_df['texts'].apply(lambda x:slipt2(x))
trains_df['summary']=trains_df['texts'].apply(lambda x:slipt2(x))
#加载到dataset并预处理
trains_ds=Dataset.from_pandas(trains_df).remove_columns(["texts","text"])
val_ds=Dataset.from_pandas(val_df).remove_columns(["texts","text"])
tokenized_trains_ds=trains_ds.map(lambda examples:fast_tokenizer(examples['summary'],truncation=True,padding=True),batched=True)
tokenized_val_ds=val_ds.map(lambda examples:fast_tokenizer(examples['summary'],truncation=True,padding=True),batched=True)
- 设置TrainingArguments和Trainer
#设置acc评估方式
from datasets import load_metric
metric = load_metric('accuracy')
def compute_metrics(eval_pred):
predictions, labels = eval_pred
predictions = np.argmax(predictions, axis=1)
return metric.compute(predictions=predictions, references=labels)
#进行任务微调
from transformers import TrainingArguments,Trainer
args=TrainingArguments(
output_dir='news-classification-2',
evaluation_strategy="epoch",
save_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=96,
per_device_eval_batch_size=96,
num_train_epochs=6,
weight_decay=0.01,
load_best_model_at_end=True,
metric_for_best_model="accuracy")
trainer=Trainer(
model,
args,
train_dataset=tokenized_trains_ds,
eval_dataset=tokenized_val_ds,
tokenizer=fast_tokenizer,
compute_metrics=compute_metrics)
==训练完GPU memory还是1.5GB==trainer.train()
trainer.save_model("./finally_bert")
==一开始训练,GPU memory跳到15.8GB(batch_size=128)。爆了之后选择分类微调模型的batch_size=16,GPU memory为3.4GB==
- 最后读取测试集,预测结果
#读取测试集并预处理
#读取测试集
import pandas as pd
from datasets import load_dataset
test_df=pd.read_csv('./test_a.csv',sep='\t')
#将训练数据中三个token换成标点
test_df['texts']=test_df['text'].map(lambda x:replacepunc(x))
#首尾截断
from datasets import Dataset
test_df['summary']=test_df['texts'].apply(lambda x:slipt2(x))
#加载到dataset并预处理
test_ds=Dataset.from_pandas(test_df).remove_columns(["texts","text"])
tokenized_test_ds=test_ds.map(lambda examples:fast_tokenizer(examples['summary'],truncation=True,padding=True),batched=True)
#用trainer预测结果并保存 |
3.4 赛事总结:
- 一开始要搞懂baseline的基本框架和config作为参考,如果比较难读不懂,可以直接跑一遍或者debug(还没有跑,有人说内存爆了。。。)
- 最开始用少量数据跑,batch_size、学习率、数据集、epoch和时长确定好再跑一遍。之前就是嫌时间太长加了batch_size结果跑到模型微调时显存崩了,所有缓存数据都没了。
- 中间数据和训练中的模型要记得保存,一旦掉线或者崩了或者想修改参数可以继续加载再跑。因为一开始不知道如何保存和加载datasets数据、kaggle的notebook老是无法保存,结果总是白跑了模型,浪费时间。
- 想到再补
零、分词tokenization
比赛数据脱敏,需要从头开始预训练。第一步就是建立词表,训练自己的分词器
参考资料:《Summary of the tokenizers》
《[NLP]——BPE、WordPiece、Unigram and SentencePiece》
==wordpiece和BPE的差异在于合并时对token对的选择:BPE是选择出现次数最大的,wordpiece衡量的是token对和单独的两个token之间的概率差,选择概率差最大的进行合并。==
考虑token a和b,以及合并之后的token ab,概率差的公式如下:
==这可以近似理解为合并前后,整个语料的互信息。即,当前选择合并的token对能够让语料的熵最小化->确定性最大化->信息量最小化->在计算机中存储所需要的编码长度最短化。==
所以如果词表中字符a和b本身次数就很高,如果合并ab的概率就算不高(比如0.1):
- 对于bpe来说ab次数多,需要合并
- 对于wordpiece,ab合并概率低,不合并
tokenizer可以将文本拆分为词或子词(即标记文本)。 🤗 Transformers 中使用的三种主要类型的分词器: Byte-Pair Encoding字节对编码 (BPE)、WordPiece 和 SentencePiece,下面展示哪个模型使用哪种分词器类型的示例。
在每个模型页面上,您可以查看相关分词器的文档以了解预训练模型使用的分词器类型。 例如,如果我们查看 BertTokenizer,我们可以看到该模型使用 WordPiece
1.2 分词规则
分词有多种方式,对于一个句子:
“Don’t you love 🤗 Transformers? We sure do.”
- 可以按空格分词:
[“Don’t”, “you”, “love”, “🤗”, “Transformers?”, “We”, “sure”, “do.”] - 区分标点:tokens和标点的各种组合会导致模型必须学习的表示数量激增,所以应该予以清理。标点处理后得到:
[“Don”, “‘“, “t”, “you”, “love”, “🤗”, “Transformers”, “?”, “We”, “sure”, “do”, “.”] - 区分缩写:“Don’t”代表“do not”,因此最好将其标记为 [“Do”, “n’t”]。这就是事情开始变得复杂的地方,也是每个模型都有自己的标记器类型的部分原因
根据我们应用于标记文本的规则,为相同的文本生成不同的标记输出。 预训练模型输入必须是,用于标记其训练数据的相同规则的标记输入,这样才能正常执行。
spaCy 和 Moses 是两种流行的基于规则的标记器。 将它们应用到我们的示例中,spaCy 和 Moses 将输出如下内容:
[“Do”, “n’t”, “you”, “love”, “🤗”, “Transformers”, “?”, “We”, “sure”, “do”, “.”]
这里使用了空格和标点符号化以及基于规则的标记化,其松散定义为将句子拆分为单词。这种标记化方法非常简单,但是可能会导致大量文本语料库出现问题,生成一个非常大的词汇表(使用的所有唯一单词和标记的集合)。例如,Transformer XL 使用空格和标点符号化,导致词汇量大小为 267,735!
如此大的词汇量迫使模型有一个巨大的嵌入矩阵作为输入和输出层,这会导致内存和时间复杂度的增加。一般来说,==transformers 模型的词汇量很少超过 50,000,尤其是当它们仅在一种语言上进行预训练时==。
那么如果简单的空格和标点符号化不能令人满意,为什么不简单地对字符char进行标记化呢?
1.3 character-based-tokenizer
字符标记化往往伴随着性能的损失,使模型学习有意义的输入表示变得更加困难。例如。 学习字母“t”的有意义的上下文比学习单词“today”的上下文无关表示要困难得多。 因此,为了两全其美,transformers 模型使用了词级和字符级标记化之间的混合,称为子词标记化。
1.4 Subword tokenization
原则:不应将常用词拆分为更小的子词,而应将稀有词分解为有意义的子词。以通过将子词串在一起来形成(几乎)任意长的复杂词。
例如,“annoyingly”可能被认为是一个罕见的词,可以分解为“annoying”和“ly”。 “annoying”和“ly”作为独立的子词出现的频率会更高,同时“annoyingly”的意思被“annoying”和“ly”的复合词所保持。
- 子词标记化允许模型具有合理的词汇量
- 同时能够学习有意义的上下文无关表示
- 使模型能够通过将它们分解为已知的子词来处理它以前从未见过的词
from transformers import BertTokenizer |
我们可以看到单词 [“i”, “have”, “a”, “new”] 出现在分词器的词汇表中,但单词“gpu”却没有。 因此,分词器将“gpu”拆分为已知的子词:[“gp”和“##u”]。 “##”表示令牌的其余部分应附加到前一个,没有空格(用于解码或逆转令牌化)。
再举一个例子,XLNetTokenizer 将我们之前的示例文本分词如下:
from transformers import XLNetTokenizer |
SentencePiece:将罕见词”Transformers” 拆分成更常见的子词 “Transform” 和 “ers”.
现在让我们看看不同的子词标记化算法是如何工作的。
1.5 Byte-Pair Encoding字节对编码 (BPE)
- Byte-Pair Encoding (BPE) 是Neural Machine Translation引入的(具有罕见词的子词units)。依赖于将训练数据拆分为word的pre-tokenizer。预标记化可以像空格化(space tokenization)一样简单,就像GPT-2, Roberta。
- 更高级的预标记化包括基于规则的标记化,例如XLM、FlauBERT(在大多数语言中使用 Moses)或 GPT(使用 Spacy 和 ftfy)来计算训练语料库中每个单词的频率。
- 在预标记化之后:
- 根据训练数据形成一系列唯一token及其出现频率
- BPE 创建一个由唯一单词集中的所有符号组成的基本词汇表
- 学习合并规则以从基本词汇表的两个符号形成一个新符号。直到词汇量达到所需的词汇量大小。请注意,==所需的词汇量是在训练分词器之前定义的超参数==。
举个例子,让我们假设在预标记化之后,已经确定了以下一组单词,包括它们的频率:
("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5) |
- 基本词汇是 [“b”, “g”, “h”, “n”, “p”, “s”, “u”]。 将所有单词拆分为基本词汇表的符号,我们得到:
("h" "u" "g", 10), ("p" "u" "g", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "u" "g" "s", 5) |
- BPE 计算每个可能的符号对的频率并选择出现频率最高的符号对。最频繁的符号对是“u”后跟“g”,总共出现 10 + 5 + 5 = 20 次,因此,分词器学习的第一个合并规则是将所有“u”符号和后跟“g”符号组合在一起。 接下来,将“ug”添加到词汇表中。 这组词然后变成:
("h" "ug", 10), ("p" "ug", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "ug" "s", 5) |
- BPE 识别下一个最常见的符号对:“u”后跟“n”16 次。 “u”, “n” 合并到 “un” 并添加到词汇表中。 下一个最频繁的符号对是“h”后跟“ug”,出现 15 次。 这对再次合并,并且可以将“hug”添加到词汇表中。
在这个阶段,词汇是 [“b”, “g”, “h”, “n”, “p”, “s”, “u”, “ug”, “un”, “hug”] 和我们的 一组独特的词表示为:
("hug", 10), ("p" "ug", 5), ("p" "un", 12), ("b" "un", 4), ("hug" "s", 5) |
- 假设字节对编码训练将在此时停止,然后将学习到的合并规则应用于新单词。例如”bug”分词成 [“b”, “ug”],但是”mug” 分词成 [“
“, “ug”]。因为词汇表不包含:“m”。
如前所述,词汇量大小,即基本词汇量大小 + 合并次数(base vocabulary size + the number of merges),是一个可供选择的超参数。 例如,GPT 的词汇量是 40,478,因为它们有 478 个基本字符,并且在 40,000 次合并后选择停止训练。
1.6 字节级 BPE(Byte-level BPE)
GPT-2 使用字节作为基础词汇,这是一个巧妙的技巧,可以强制基础词汇的大小为 256,同时确保每个基础字符都包含在词汇中。再加上一些额外的标点符号处理规则,GPT-2的分词器不需要\
GPT-2 的词汇量大小为 50,257,对应于 256 字节的基本标记、一个特殊的文本结束标记和通过 50,000 次合并学习的符号。
1.7 WordPiece
WordPiece 是用于 BERT、DistilBERT 和 Electra 的子词标记化算法,与 BPE 非常相似。 WordPiece 首先初始化词汇表以包含训练数据中存在的每个字符,并逐步学习给定数量的合并规则。==与 BPE 相比,WordPiece 不选择最频繁的符号对,而是选择将训练数据添加到词汇表中的可能性最大化的符号对==。
那么这到底是什么意思呢?参考前面的例子,最大化训练数据的似然性相当于找到符号对,其概率除以其第一个符号后跟第二个符号的概率在所有符号对中最大。例如。只有当“ug”除以“u”、“g”的概率大于任何其他符号对时,“u”和“g”才会被合并。直观地说,WordPiece 与 BPE 略有不同,它通过合并两个符号来评估它的损失,以确保it’s worth it。
1.8 Unigram
- 基本词汇表可以对应于所有预先标记的单词和最常见的子串
- 删除了损失增加最低的符号,重复这个过程,直到词汇量达到所需的大小。
Unigram 是在 Subword 正则化:与 BPE 或 WordPiece 相比,==Unigram 将其基本词汇表初始化为大量符号,并逐步缩减每个符号以获得较小的词汇表。例如,基本词汇表可以对应于所有预先标记的单词和最常见的子串==。 Unigram 不直接用于transformers中的任何模型,但它与 SentencePiece 结合使用。
在每个训练步骤中,Unigram 算法在给定当前词汇和 unigram 语言模型的情况下定义训练数据的损失(通常定义为对数似然)。然后,==对于词汇表中的每个符号,算法计算如果要从词汇表中删除该符号,总体损失会增加多少。然后 Unigram 删除了损失增加最低的符号的 概率p(通常为 10% 或 20%),即那些对训练数据的整体损失影响最小的符号。重复这个过程,直到词汇量达到所需的大小。== Unigram 算法始终保留基本字符,以便可以对任何单词进行标记。
由于 Unigram 不基于合并规则(与 BPE 和 WordPiece 不同),因此该算法有多种方法可以在训练后对新文本进行标记。例如,如果经过训练的 Unigram 分词器展示词汇表:
["b", "g", "h", "n", "p", "s", "u", "ug", "un", "hug"], |
“hug”可以标记为 [“hug”, “s”], [“h”, “ug”, “s”] 或 [“h”, “u”, “g”, “s”]。 那么该选择哪一个呢? Unigram 在保存词汇的基础上还保存了训练语料库中每个标记的概率,以便在训练后计算每个可能的标记化的概率。 该算法在实践中只是简单地选择最可能的标记化,但也提供了根据概率对可能的标记化进行采样的可能性。
这些概率由分词器训练的损失定义。 假设训练数据由单词 x1,…,xN 组成,并且单词 xi 的所有可能标记的集合被定义为 S(xi),那么总损失定义为: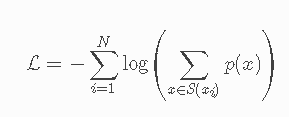
1.9 SentencePiece
到目前为止描述的所有标记化算法都有相同的问题:==假设输入文本使用空格来分隔单词==。
但是,并非所有语言都使用空格来分隔单词,例如中文、日文和泰文。
一种可能的解决方案是使用特定于语言的预分词器,例如XLM 使用特定的预分词器。SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing (Kudo et al., 2018) 将输入视为原始输入流,thus including the space in the set of characters to use.然后它使用 BPE 或 unigram 算法来构建适当的词汇表。
例如,XLNetTokenizer 中使用的 SentencePiece,解码非常容易,因为所有标记都可以连接起来,并且“-” 被空格替换。 SentencePiece 和unigram 结合使用,包括 ALBERT、XLNet、Marian 和 T5。
本文参考:how_to_train.ipynb
一、训练分词器
1.1 Using tokenizers from 🤗 Tokenizers
参考文档:HF文档
PreTrainedTokenizerFast 依赖于 tokenizers 库。 从 🤗 Tokenizers 库中获得的分词器可以非常简单地加载到 🤗 Transformers 中。
在详细介绍之前,让我们首先在几行中创建一个虚拟标记器:from tokenizers import Tokenizer
from tokenizers.models import BPE
from tokenizers.trainers import BpeTrainer
from tokenizers.pre_tokenizers import Whitespace
tokenizer = Tokenizer(BPE(unk_token="[UNK]"))
trainer = BpeTrainer(special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
tokenizer.pre_tokenizer = Whitespace()
files = [...]
tokenizer.train(files, trainer)
现在有了一个我们定义的标记器,可以继续使用,或者将它保存到一个 JSON 文件中以备将来重用。
- 直接以tokenizer object使用
from transformers import PreTrainedTokenizerFast |
- json文件加载使用
tokenizer.save("tokenizer.json") |
1.2 Train your tokenizer
Transformers Notebooks——How to train and use your very own tokenizer
1.2.1 从头训练分词器
给定语料库上训练分词器,进而从头训练transformer模型。 在tokenizers summary 中可以查看子词分词算法之间的差异(也就是上一节内容)。
下面举例使用wikitext数据集(包含 4.5MB 的文本,所以我们的例子训练速度很快)训练分词器:
from datasets import load_dataset |
训练我们的分词器的 API 将需要一批文本的迭代器,例如文本列表:batch_size = 1000
all_texts = [dataset[i : i + batch_size]["text"] for i in range(0, len(dataset), batch_size)]
为了避免将所有内容加载到内存中(因为 Datasets 库将元素保存在磁盘上并且仅在请求时将它们加载到内存中),我们定义了一个 Python 迭代器来进行批处理:
def batch_iterator(): |
接下来有两种方法训练分词器:
- 使用现有的分词器,一行代码就可以在给定数据集上训练新的分词器
- 逐块构建分词器,因此可以自定义每一步 !
1.2.2 使用已有的分词器训练
如果您想使用与现有算法完全相同的算法和参数来训练一个分词器,您可以只使用 train_new_from_iterator API。 例如,让我们使用相同的标记化算法在 Wikitext-2 上训练新版本的 GPT-2 tokenzier。
首先,我们需要加载我们想要用作模型的tokenizer:
from transformers import AutoTokenizer |
确保您选择的标记器是快速版本(由 🤗 Tokenizers 库支持),否则 notebook 的其余部分将无法运行:
tokenizer.is_fast |
然后我们将训练语料库(list of list或我们之前定义的迭代器)提供给 train_new_from_iterator 方法。 我们还必须指定要使用的词汇量大小:
new_tokenizer = tokenizer.train_new_from_iterator(batch_iterator(), vocab_size=25000) |
到此就完成了分词器的训练。由于使用了Rust 支持的 🤗 Tokenizers 库,训练进行得非常快。
您现在有一个新的标记器可以预处理您的数据并训练语言模型。 您可以像往常一样输入输入文本:
new_tokenizer(dataset[:5]["text"]) |
保存模型:
new_tokenizer.save_pretrained("my-new-tokenizer") |
之后可以加载此分词器:
tok = new_tokenizer.from_pretrained("my-new-tokenizer") |
或者推送到 Hugging Face Hub 以从任何地方使用这个新的 tokenzier,具体操作参考此处。
1.2.3 从头构建分词器
如果你想创建和训练一个新的标记器,它看起来不像现有的任何东西,你需要使用 🤗 Tokenizers 库从头开始构建它.
要了解如何从头开始构建标记器,我们必须深入了解 🤗 Tokenizers 库和标记化管道。 此管道需要几个步骤:
- Normalization:对初始输入字符串执行所有初始转换。 例如,当您需要小写某些文本时,可能会将其剥离,甚至应用一种常见的 unicode 规范化过程,您将添加一个 Normalizer。
- Pre-tokenization:负责分割初始输入字符串。 这是决定在何处以及如何对原始字符串进行预分段的组件。 最简单的例子是使用空格进行分割。
pre_tokenizers?? |
- model:处理所有sub-token的发现和生成,这是可训练且真正依赖于您的输入数据的部分。
models?? |
- 后处理Post-Processing:提供与一些基于 Transformers 的 SoTA 模型兼容的高级构建功能。 例如,对于 BERT,它会将标记化的句子包裹在 [CLS] 和 [SEP] 标记周围。
processors?? |
- 解码Decoding:负责将标记化的输入映射回原始字符串。 通常根据我们之前使用的 PreTokenizer 来选择解码器。
decoders?? |
对于模型的训练,🤗 Tokenizers 库提供了一个我们将使用的 Trainer 类。
trainers??
BPE = trainers.BPE
Unigram = trainers.Unigram
WordLevel = trainers.WordLevel
WordPiece = trainers.WordPiece
所有这些构建块都可以组合起来创建tokenization pipelines。 下面将展示三个完整的管道:GPT-2、BERT 和 T5(它将为你提供 BPE、WordPiece 和 Unigram 标记器的示例)。
1.2.3.2 WordPiece model like BERT
创建一个 WordPiece 标记器(like BERT):
- 创建一个带有空 WordPiece 模型的 Tokenizer:
from tokenizers import decoders, models, normalizers, pre_tokenizers, processors, trainers, Tokenizer |
- 添加normalization(可选)
tokenizer.normalizer = normalizers.BertNormalizer(lowercase=True) |
- 添加pre-tokenizer(分词)
#直接使用 BertPreTokenizer,它使用空格和标点符号预先标记: |
与 normalizer 一样,我们可以在一个 Sequence 中组合多个 pre-tokenizer。 如果我们想快速了解它如何预处理输入,我们可以调用 pre_tokenize_str 方法:
tokenizer.pre_tokenizer.pre_tokenize_str("This is an example!") |
请注意,==pre-tokenizer 不仅将文本拆分为单词,还保留了偏移量==,即原始文本中每个单词的开头和开头。 这将使最终的分词器==能够将每个标记与它来自的文本部分进行匹配(我们用于问答或标记分类任务的功能)==。
special_tokens = ["[UNK]", "[PAD]", "[CLS]", "[SEP]", "[MASK]"] |
- 构建数据集(text files)或批处理工具(batches of texts):
tokenizer.train_from_iterator(batch_iterator(), trainer=trainer) |
- 分词器已经训练完毕,定义后处理器:开头添加 CLS 标记并在末尾添加 SEP 标记(对于单个句子)或几个 SEP 标记(对于句子对)。 可以使用 TemplateProcessing 来做到这一点。
#获取CLS 和SEP 的token id |
下面编码一个句子看看结果:
encoding = tokenizer.encode("This is one sentence.", "With this one we have a pair.") |
- 解码器:我们使用 WordPiece 解码器并指示特殊前缀 ##:
tokenizer.decoder = decoders.WordPiece(prefix="##") |
现在我们的tokenizer已经完成,我们必须将它放在与我们要使用的模型相对应的标记器 fast 类中,这里是一个 BertTokenizerFast:
from transformers import BertTokenizerFast |
和以前一样,我们可以将此分词器用作普通的 Transformers 分词器,并使用 save_pretrained 或 push_to_hub 方法。
如果您正在构建的分词器与 Transformers 中的任何类都不匹配(分词器非常特殊),您可以将它包装在 PreTrainedTokenizerFast 中。
1.2.3.3 BPE model like GPT-2
下面看看如何创建一个 BPE 标记器(like GPT-2 tokenizer):
- 创建一个带有初始 BPE model的 Tokenizer:
tokenizer = Tokenizer(models.BPE()) |
- 添加可选normalization(GPT2不使用)
- 指定pre-tokenizer(GPT2使用byte level pre-tokenizer)
tokenizer.pre_tokenizer = pre_tokenizers.ByteLevel(add_prefix_space=False) |
调用 pre_tokenize_str 方法,快速了解它如何预处理输入:
tokenizer.pre_tokenizer.pre_tokenize_str("This is an example!") |
我们对前缀空格使用 GPT-2的默认值,所以除了第一个单词之外,每个单词的开头都添加了一个首字母“Ġ”。
- 使用 BpeTrainer训练分词器:
trainer = trainers.BpeTrainer(vocab_size=25000, special_tokens=["<|endoftext|>"]) |
- 添加后处理和解码器:
tokenizer.post_processor = processors.ByteLevel(trim_offsets=False) |
- 将此分词器包装在 Transformers tokenizer object中:
from transformers import GPT2TokenizerFast |
1.2.3.4 Unigram model like Albert
现在让我们看看如何创建一个 Unigram 分词器(类似 T5 的分词器):
- 创建 初始Unigram 模型的 Tokenizer:
tokenizer = Tokenizer(models.Unigram()) |
- 添加normalization 和pre-tokenizer(Metaspace pre-tokenizer:它用一个特殊字符(默认为“▁” )替换所有空格,然后在该字符上拆分。)
tokenizer.normalizer = normalizers.Sequence( |
调用 pre_tokenize_str 方法,快速了解它如何预处理输入:
tokenizer.pre_tokenizer.pre_tokenize_str("This is an example!") |
每个单词都在开头添加了一个首字母“ ▁”,这是由 sentencepiece完成的。
- 使用 UnigramTrainer训练分词器,并设置unknown token。
trainer = trainers.UnigramTrainer(vocab_size=25000, special_tokens=["[CLS]", "[SEP]", "<unk>", "<pad>", "[MASK]"], unk_token="<unk>") |
- 添加后处理和解码器(Metaspace,类似pre-tokenizer)
cls_token_id = tokenizer.token_to_id("[CLS]") |
- 将此分词器包装在 Transformers tokenizer object中:
from transformers import AlbertTokenizerFast |
现在可以用新的tokenizer训练模型了。
- 使用新的分析器在notebook上从头训练模型
- 在language modeling scripts 上使用tokenizer_name参数来从头训练模型。
二、HF模型预训练方式
使用HF主页的tokenizer和MLM包,进行trainer训练1.加载数据集:
选择多语言多语料数据集OSCAR corpus# in this notebook we'll only get one of the files (the Oscar one) for the sake of simplicity and performance
!wget -c https://cdn-datasets.huggingface.co/EsperBERTo/data/oscar.eo.txt2.训练tokenizer
选择字节级别byte-level BPE分词器(类似GPT2使用的),比BERT的WordPiece(字符级别BPE分词器,切分成子词)好处是几乎不会有未登录词”\tokens”。
# 安装transformers和tokenizers |
%%time |
2.2 分词器的训练参数如下:
#BPE的分词器 |
- vocab_size (int, optional) – 最终词汇的大小,包括所有标记和字母表。
- min_frequency (int, optional) – 为了合并,一对应该具有的最小频率。
- show_progress (bool, optional) – 训练时是否显示进度条。
- special_tokens (List[Union[str,AddedToken]], optional) – 模型应该知道的特殊标记列表。
- limit_alphabet (int, optional) – 字母表中保留的最大不同字符数。
- initial_alphabet (List[str], optional) – 包含在初始字母表中的字符列表,即使在训练数据集中没有出现。 如果字符串包含多个字符,则仅保留第一个字符。
- continue_subword_prefix (str, optional) — 用于每个不是词开头的子词的前缀。
- end_of_word_suffix (str, optional) – 用于每个词尾的子词的后缀。
#WordPiece分词器,参数和上一个相同 |
- vocab_size (int, optional) – 最终词汇的大小,包括所有标记和字母表。
- min_frequency (int, optional) – 为了合并,一对应该具有的最小频率。
- show_progress (bool, optional) – 训练时是否显示进度条。
- special_tokens (List[Union[str,AddedToken]], optional) – 模型应该知道的特殊标记列表。
- limit_alphabet (int, optional) – 字母表中保留的最大不同字符数。
- initial_alphabet (List[str], optional) – 包含在初始字母表中的字符列表,即使在训练数据集中没有出现。 如果字符串包含多个字符,则仅保留第一个字符。
- continue_subword_prefix (str, optional) — 用于每个不是词开头的子词的前缀。
- end_of_word_suffix (str, optional) – 用于每个词尾的子词的后缀。
2.3 分词器保存和加载
将训练好的分词器保存在EsperBERTo文件夹:
!mkdir EsperBERTo |
最终得到两个分词器文件:
- EsperBERTo/vocab.json:vocab.json,按频率排列的常见token的列表
- EsperBERTo/merges.txt’: merges.txt,merges列表
{ "<s>": 0,"<pad>": 1,"</s>": 2,"<unk>": 3, "<mask>": 4,"!": 5,"\"": 6,"#": 7, |
tokenizer针对Esperanto进行了优化,更多单词是a single, unsplit token表示。==我们还以更有效的方式表示序列。 在这个语料库中,编码序列的平均长度比使用预训练的 GPT-2 标记器时小约 30%。==
加载分词器,处理 RoBERTa 特殊标记:from tokenizers.implementations import ByteLevelBPETokenizer
from tokenizers.processors import BertProcessing
tokenizer = ByteLevelBPETokenizer(
"./EsperBERTo/vocab.json",
"./EsperBERTo/merges.txt",
)
tokenizer._tokenizer.post_processor = BertProcessing( |
token_to_id:将给定的token转换为其对应的 id
BertProcessing参数:
classtokenizers.processors.BertProcessing(self, sep, cls) |
这个后处理器负责添加 Bert 模型所需的特殊标记:
- sep (Tuple[str, int]) – 带有 SEP 令牌的字符串表示及其 id 的元组
- cls (Tuple[str, int]) – 一个带有 CLS 标记的字符串表示的元组,以及它的 id
测试效果:
tokenizer.encode("Mi estas Julien.") |
tokenizer.encode("Mi estas Julien.").tokens |
3.从头开始训练语言模型
参考run_language_modeling.py 文件。直接设置 Trainer 选择训练方法。下面以训练类似 RoBERTa 的模型来举例:(相比bert采用动态掩码、舍弃NSP任务,以及更大的训练)
import torch |
3.2 初始化模型
由于我们是从头开始训练,因此我们仅从配置进行初始化,而不是从现有的预训练模型或检查点进行初始化。
from transformers import RobertaForMaskedLM |
3.3 创建训练集
由于只有一个text文件,不需要自定义数据集。直接使用LineByLineDataset加载之后用tokenizer预处理。
%%time |
定义data_collator:帮助我们将数据集样本进行批处理的数据整理器。 如果输入的长度不同,则输入会动态填充到批次的最大长度。
from transformers import DataCollatorForLanguageModeling |
class transformers.data.data_collator.DataCollatorForLanguageModeling(tokenizer: transformers.tokenization_utils_base.PreTrainedTokenizerBase, mlm: bool = True, mlm_probability: float = 0.15, pad_to_multiple_of: Optional[int] = None, tf_experimental_compile: bool = False, return_tensors: str = 'pt') |
- tokenizer(PreTrainedTokenizer 或 PreTrainedTokenizerFast)——用于编码数据的标记器。
- mlm (bool, optional, defaults to True) – 是否使用掩码语言建模。 如果设置为 False,则标签与忽略填充标记的输入相同(通过将它们设置为 -100)。 否则,non-masked tokens 的label和masked token的预测值为 -100。(If set to False, the labels are the same as the inputs with the padding tokens ignored (by setting them to -100). Otherwise, the labels are -100 for non-masked tokens and the value to predict for the masked token.)
- mlm_probability(浮点数,可选,默认为 0.15)– 当 mlm 设置为 True 时(随机)屏蔽输入中的标记的概率。
- pad_to_multiple_of (int, optional) – 如果设置,则将序列填充为所提供值的倍数。
3.4 初始化 Trainer并训练
from transformers import Trainer, TrainingArguments |
开始训练%%time
trainer.train()
CPU times: user 1h 43min 36s, sys: 1h 3min 28s, total: 2h 47min 4s
Wall time: 2h 46min 46s
TrainOutput(global_step=15228, training_loss=5.762423221226405)
保存模型
trainer.save_model("./EsperBERTo") |
5. 检查训练好的模型
除了查看训练和评估损失下降之外,可以通过FillMaskPipeline加载模型进行预测
from transformers import pipeline |
# The sun <mask>. |
[{'score': 0.02119220793247223, |
最后,当你有一个不错的模型时,请考虑与社区分享:
使用 CLI 上传您的模型:transformers-cli upload
写一个 README.md 模型卡并将其添加到 model_cards/ 下的存储库中。 理想情况下,您的模型卡应包括:
- 模型描述
- 训练参数(数据集、预处理、超参数)
- 评估结果
- 预期用途和限制
- 其它有用信息 🤓