
CLUENER 细粒度命名实体识别
一、任务说明:
- 最开始是参考知乎文章《用BERT做NER?教你用PyTorch轻松入门Roberta!》,github项目地址:《hemingkx/CLUENER2020》
- 任务介绍:本任务是中文语言理解测评基准(CLUE)任务之一:《CLUE Fine-Grain NER》。
- 数据来源:本数据是在清华大学开源的文本分类数据集THUCTC基础上,选出部分数据进行细粒度命名实体标注,原数据来源于Sina News RSS.
- 平台github任务详情:《CLUENER 细粒度命名实体识别》
- CLUE命名实体任务排行榜
- BERT-base-X部分的代码编写思路参考 lemonhu
- 参考文章《中文NER任务简析与深度算法模型总结和实战展示》
二、数据集介绍:
cluener下载链接:数据下载
2.1 数据集划分和数据内容
- 训练集:10748
- 验证集:1343
- 测试集(无标签):1345
- 原始数据存储在json文件中。文件中的每一行是一条单独的数据,一条数据包括一个原始句子以及其上的标签,具体形式如下:
展开看就是:
{"text": "生生不息CSOL生化狂潮让你填弹狂扫", "label": {"game": {"CSOL": [[4, 7]]}}}数据字段解释:
"text": "浙商银行企业信贷部叶老桂博士则从另一个角度对五道门槛进行了解读。叶老桂认为,对目前国内商业银行而言,",
"label": {
"name": {
"叶老桂": [
[9, 11],
[32, 34]
]
},
"company": {
"浙商银行": [
[0, 3]
]
}
}
}
以train.json为例,数据分为两列:text & label,其中text列代表文本,label列代表文本中出现的所有包含在10个类别中的实体。例如:
label: {"organization": {"北京勘察设计协会": [[0, 7]]}, "name": {"周荫如": [[15, 17]]}, "position": {"副会长": [[8, 10]], "秘书长": [[12, 14]]}}
其中,organization,name,position代表实体类别,
"organization": {"北京勘察设计协会": [[0, 7]]}:表示原text中,"北京勘察设计协会" 是类别为 "组织机构(organization)" 的实体, 并且start_index为0,end_index为7 (注:下标从0开始计数)
"name": {"周荫如": [[15, 17]]}:表示原text中,"周荫如" 是类别为 "姓名(name)" 的实体, 并且start_index为15,end_index为17
"position": {"副会长": [[8, 10]], "秘书长": [[12, 14]]}:表示原text中,"副会长" 是类别为 "职位(position)" 的实体, 并且start_index为8,end_index为10,同时,"秘书长" 也是类别为 "职位(position)" 的实体,
并且start_index为12,end_index为14
2.2 标签类别和定义:
数据分为10个标签类别,分别为: 地址(address),书名(book),公司(company),游戏(game),政府(goverment),电影(movie),姓名(name),组织机构(organization),职位(position),景点(scene) |
- 标签定义与规则:
地址(address): **省**市**区**街**号,**路,**街道,**村等(如单独出现也标记),注意:地址需要标记完全, 标记到最细。
书名(book): 小说,杂志,习题集,教科书,教辅,地图册,食谱,书店里能买到的一类书籍,包含电子书。
公司(company): **公司,**集团,**银行(央行,中国人民银行除外,二者属于政府机构), 如:新东方,包含新华网/中国军网等。
游戏(game): 常见的游戏,注意有一些从小说,电视剧改编的游戏,要分析具体场景到底是不是游戏。
政府(goverment): 包括中央行政机关和地方行政机关两级。 中央行政机关有国务院、国务院组成部门(包括各部、委员会、中国人民银行和审计署)、国务院直属机构(如海关、税务、工商、环保总局等),军队等。
电影(movie): 电影,也包括拍的一些在电影院上映的纪录片,如果是根据书名改编成电影,要根据场景上下文着重区分下是电影名字还是书名。
姓名(name): 一般指人名,也包括小说里面的人物,宋江,武松,郭靖,小说里面的人物绰号:及时雨,花和尚,著名人物的别称,通过这个别称能对应到某个具体人物。
组织机构(organization): 篮球队,足球队,乐团,社团等,另外包含小说里面的帮派如:少林寺,丐帮,铁掌帮,武当,峨眉等。
职位(position): 古时候的职称:巡抚,知州,国师等。现代的总经理,记者,总裁,艺术家,收藏家等。
景点(scene): 常见旅游景点如:长沙公园,深圳动物园,海洋馆,植物园,黄河,长江等。2.3 数据分布
训练集:10748 验证集:1343
按照不同标签类别统计,训练集数据分布如下(注:一条数据中出现的所有实体都进行标注,如果一条数据出现两个地址(address)实体,那么统计地址(address)类别数据的时候,算两条数据):
【训练集】标签数据分布如下:地址(address):2829
书名(book):1131
公司(company):2897
游戏(game):2325
政府(government):1797
电影(movie):1109
姓名(name):3661
组织机构(organization):3075
职位(position):3052
景点(scene):1462
【验证集】标签数据分布如下:
地址(address):364
书名(book):152
公司(company):366
游戏(game):287
政府(government):244
电影(movie):150
姓名(name):451
组织机构(organization):344
职位(position):425
景点(scene):199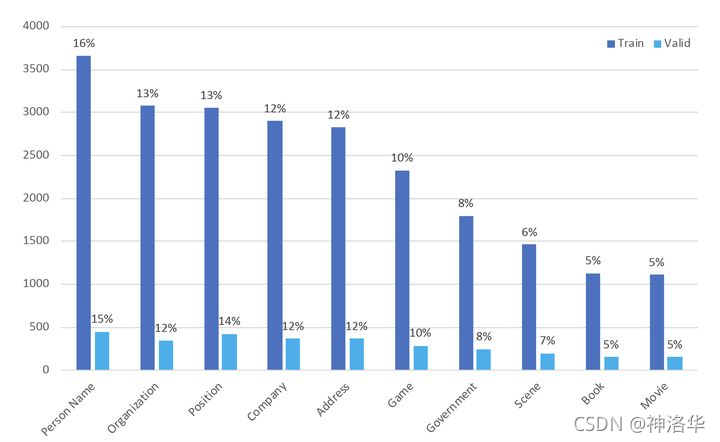
测试训练集句子长度%pylab inline
#最大句子长度50
train_df['text_len'] = train_df['words'].apply(lambda x: len(x))
print(train_df['text_len'].describe())
Populating the interactive namespace from numpy and matplotlib |
平台测试结果:
Roberta指的chinese_roberta_wwm_large模型。(roberta-wwm-large-ext)
模型 BiLSTM+CRF bert-base-chinese Roberta+Softmax Roberta+CRF Roberta+BiLSTM+CRF |
可见,Roberta+lstm和Roberta模型差别不大。
官方处理方法:softmax、crf和span,模型本体和运行代码见:CLUENER2020/pytorch_version/models/albert_for_ner.py | run_ner_crf.py。
为什么使用CRF提升这么大呢? softmax最终分类,只能通过输入判断输出,但是 CRF 可以通过学习转移矩阵,看前后的输出来判断当前的输出。这样就能学到一些规律(比如“O 后面不能直接接 I”“B-brand 后面不可能接 I-color”),这些规律在有时会起到至关重要的作用。
例如下面的例子,A 是没加 CRF 的输出结果,B 是加了 CRF 的输出结果,一看就懂不细说了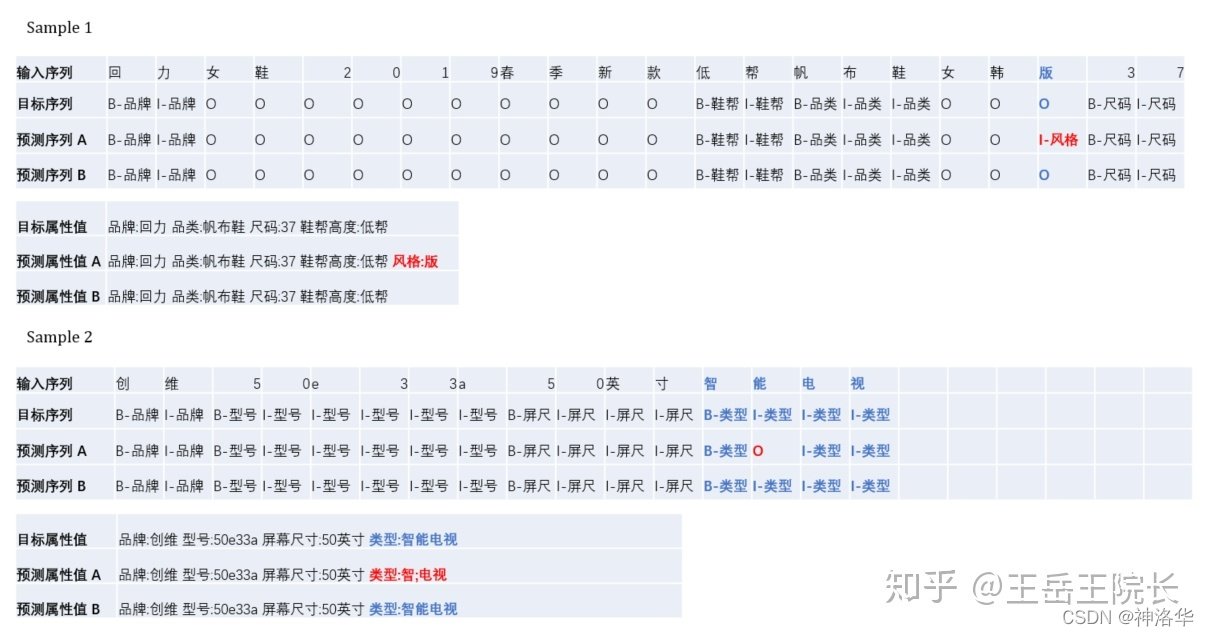
三、处理json文件,转成BIOS标注
本文选取Roberta+lstm+lstm,标注方法选择BIOS。
“B”:(实体开始的token)前缀
“I” :(实体中间的token)前缀
“O”:无特别实体(no special entity)
“S”: 即Single,“S-X”表示该字单独标记为X标签
另外还有BIO、BIOE(“E-X”表示该字是标签X的词片段末尾的终止字)等。
3.1 分词和标签预处理
NER作为序列标注任务,输出需要确定实体边界和类型。如果预先进行了分词处理,由于分词工具原本就无法保证绝对正确的分词方案,势必会产生错误的分词结果,而这将进一步影响序列标注结果。因此,我们不进行分词,在字层面进行BIOS标注。
我们采用BIOS标注对原始标签进行转换。B-X 代表实体X的开头,I-X代表实体的结尾,O代表不属于任何类型,S表示改词本身就是一个实体。范例:{"text": "浙商银行企业信贷部叶老桂博士则从另一个角度对五道门槛进行了解读。叶老桂认为,对目前国内商业银行而言,",
"label": {"name": {"叶老桂": [[9, 11],[32, 34]]}, "company": {"浙商银行": [[0, 3]]}}}
转换结果为:
['B-company', 'I-company', 'I-company', 'I-company', 'O', 'O', 'O', 'O', 'O', 'B-name', 'I-name', 'I-name', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'B-name', 'I-name', 'I-name', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O'] |
这部分处理在data_process.ipynb文件中。
labels = ['address', 'book', 'company', 'game', 'government',
'movie', 'name', 'organization', 'position', 'scene']
label2id = {
"O": 0,
"B-address": 1,
"B-book": 2,
"B-company": 3,
'B-game': 4,
'B-government': 5,
'B-movie': 6,
'B-name': 7,
'B-organization': 8,
'B-position': 9,
'B-scene': 10,
"I-address": 11,
"I-book": 12,
"I-company": 13,
'I-game': 14,
'I-government': 15,
'I-movie': 16,
'I-name': 17,
'I-organization': 18,
'I-position': 19,
'I-scene': 20,
"S-address": 21,
"S-book": 22,
"S-company": 23,
'S-game': 24,
'S-government': 25,
'S-movie': 26,
'S-name': 27,
'S-organization': 28,
'S-position': 29,
'S-scene': 30
}
id2label = {_id: _label for _label, _id in list(label2id.items())}
3.2 模型输入
再将BIOS标记转换为数字,pad之后装入dataloader输入模型。#每个句子都被pad到52的长度
train_df['label_len'] = train_df['pad_labels'].apply(lambda x: len(x))
print(train_df['label_len'].describe())
count 10748.0
mean 52.0
std 0.0
min 52.0
25% 52.0
50% 52.0
75% 52.0
max 52.0
Name: label_len, dtype: float64
words labels |
四、定义bert模型、优化器、和训练部分
这部分代码在bert_softmax.ipynb和bert_lstm_crf.ipynb文件中。
4.1 bert-softmax:
训练过程为:

验证集分数为:

训练完,用模型预测验证集结果,与原标签对比

4.2 bert+lstm+CRF
epoch6的时候f1=0.78,没有达到预期,还需要调整。