
参考datawhale课程《集成学习》
参考《Stacking方法详解》
Bagging思想的实质是:通过Bootstrap 的方式对全样本数据集进行抽样得到抽样子集,对不同的子集使用同一种基本模型进行拟合,然后投票得出最终的预测。Bagging主要通过降低方差的方式减少预测误差
一、投票法与bagging
1.1 投票法的原理分析
投票法是一种遵循少数服从多数原则的集成学习模型,通过多个模型的集成降低方差,从而提高模型的鲁棒性。在理想情况下,投票法的预测效果应当优于任何一个基模型的预测效果。
- 回归投票法:预测结果是所有模型预测结果的平均值。
- 分类投票法:预测结果是所有模型种出现最多的预测结果。
分类投票法又可以被划分为硬投票与软投票:
- 硬投票:预测结果是所有投票结果最多出现的类。(基模型能预测出清晰的类别标签时)
- 软投票:预测结果是所有投票结果中概率加和最大的类。(基模型能预测类别的概率,或可以输出类似于概率的预测分数值,例如支持向量机、k-最近邻和决策树等) 相对于硬投票,软投票法考虑到了预测概率这一额外的信息,因此可以得出比硬投票法更加准确的预测结果。
想要投票法产生较好的结果,基模型需要满足两个条件:
- 基模型之间的效果不能差别过大。</font >当某个基模型相对于其他基模型效果过差时,该模型很可能成为噪声。
- 基模型之间同质性较小。</font >例如在基模型预测效果近似的情况下,基于树模型与线性模型的投票,往往优于两个树模型或两个线性模型。
投票法的局限性:所有模型对预测的贡献是一样的。
1.2 Voting案例分析
- Sklearn中提供了 VotingRegressor 与 VotingClassifier 两个投票方法。这两种模型的操作方式相同,并采用相同的参数。
- 使用模型需要提供一个模型列表,列表中每个模型采用Tuple的结构表示,第一个元素代表名称,第二个元素代表模型,需要保证每个模型必须拥有唯一的名称。
例如这里,我们定义两个模型:
from sklearn.linear_model import LogisticRegression |
创建一个1000个样本,20个特征的随机数据集:
# test classification dataset |
我们使用多个KNN模型作为基模型演示投票法,其中每个模型采用不同的邻居值K参数:
# get a voting ensemble of models |
创建一个模型列表来评估投票带来的提升,包括KNN模型配置的每个独立版本和硬投票模型。下面的get_models()函数可以为我们创建模型列表进行评估。
# get a list of models to evaluate |
evaluate_model()函数接收一个模型实例,并以分层10倍交叉验证三次重复的分数列表的形式返回。
# evaluate a give model using cross-validation |
报告每个算法的平均性能,还可以创建一个箱形图和须状图来比较每个算法的精度分数分布。
from sklearn.neighbors import KNeighborsClassifier |
结果如下:
knn1 0.873 (0.030)
knn3 0.889 (0.038)
knn5 0.895 (0.031)
knn7 0.899 (0.035)
knn9 0.900 (0.033)
hard_voting 0.902 (0.034)

![]()
显然投票的效果略大于任何一个基模型。
通过箱形图我们可以看到硬投票方法对交叉验证整体预测结果分布带来的提升。
1.3 bagging的原理分析
Voting法希望各个模型之间具有较大的差异性,而在实际操作中的模型却往往是同质的,故考虑是通过不同的采样增加模型的差异性。</font >
自助采样(bootstrap):有放回的从数据集中进行采样。
Bagging思想的实质是:通过Bootstrap 的方式对全样本数据集进行抽样得到抽样子集,对不同的子集使用同一种基本模型进行拟合,然后投票得出最终的预测。Bagging主要通过降低方差的方式减少预测误差
bagging流程:
- 随机取出一个训练样本放入采样集合中,再把这个样本放回初始数据集,重复K次采样,最终得到大小为K的样本集合。
- 重复以上步骤采样出T个含K个样本的采样集合,然后基于每个采样集合训练出一个基学习器
- 将这些基学习器进行结合。
- 预测回归问题:预测值取平均来进行的。
- 预测分类问题:预测值投票取多数票
Bagging同样是一种降低方差的技术,因此它在不剪枝决策树、神经网络等易受样本扰动的学习器上效果更加明显。</font >在实际的使用中,加入列采样的Bagging技术对高维小样本往往有神奇的效果。
1.4 决策树和随机森林
Sklearn为我们提供了 BaggingRegressor 与 BaggingClassifier 两种Bagging方法的API,默认基模型是决策树模型。
- 决策树,它是一种树形结构,树的每个非叶子节点表示对样本在一个特征上的判断,节点下方的分支代表对样本的划分。
- 决策树的建立过程是一个对数据不断划分的过程。
- 每次划分中,首先要选择用于划分的特征,之后要确定划分的方案(类别/阈值)。我们希望通过划分,决策树的分支节点所包含的样本“纯度”尽可能地高。节点划分过程中所用的指标主要是信息增益和GINI系数。
- 选择信息增益最大或者gini指数最小的划分方式
- 划分过程直到样本的类别被完全分开,所有特征都已使用,或达到树的最大深度为止。

Bagging的一个典型应用是随机森林。由许多“树”bagging组成的。每个决策树训练的样本和构建决策树的特征都是通过随机采样得到的,随机森林的预测结果是多个决策树输出的组合(投票)</font >。随机森林的示意图如下:
1.5 bagging案例分析
- 创建一个含有1000个样本20维特征的随机分类数据集:
# test classification dataset |
- 使用重复的分层k-fold交叉验证来评估该模型,一共重复3次,每次有10个fold。我们将评估该模型在所有重复交叉验证中性能的平均值和标准差。
# evaluate bagging algorithm for classification |
最终模型的效果是Accuracy: 0.856 标准差0.037
二、stacking
stacking被称为“懒人”算法,因为它不需要花费过多时间的调参就可以得到一个效果不错的算法。
Stacking集成算法可以理解为一个两层的集成,第一层含有多个基础分类器,把预测的结果(元特征)提供给第二层, 而第二层的分类器通常是逻辑回归,他把一层分类器的结果当做特征做拟合输出预测结果。
2.1 Blending算法原理
Blending集成学习方式:
- (1) 将数据划分为训练集和测试集(test_set),其中训练集需要再次划分为训练集(train_set)和验证集(val_set);
- (2) 创建第一层的多个模型(同质异质都可),使用train_set进行训练。然后用训练好的模型预测val_set和test_set得到val_predict, test_predict1
- (3) 创建第二层的模型(一般是LR),使用val_predict作为训练集,验证集val_set的标签作为标签训练第二层的模型;
- (4) 使用第二层训练好的模型对第二层测试集test_predict1进行预测</font >,该结果为整个测试集的结果。

Blending集成方式的优劣: - 最重要的优点就是实现简单粗暴,没有太多的理论的分析。
- 缺点:只使用了一部分数据集作为留出集进行验证,也就是只能用上数据中的一部分,进而容易产生过拟合。
2.2 Blending案例
# 加载相关工具包 |
# 设置第一层分类器 |
每一折的交叉验证的效果都是非常好的,这个集成学习方法在这个数据集上是十分有效的,不过这个数据集是我们虚拟的,因此大家可以把他用在实际数据上看看效果。
2.3 Stacking算法原理
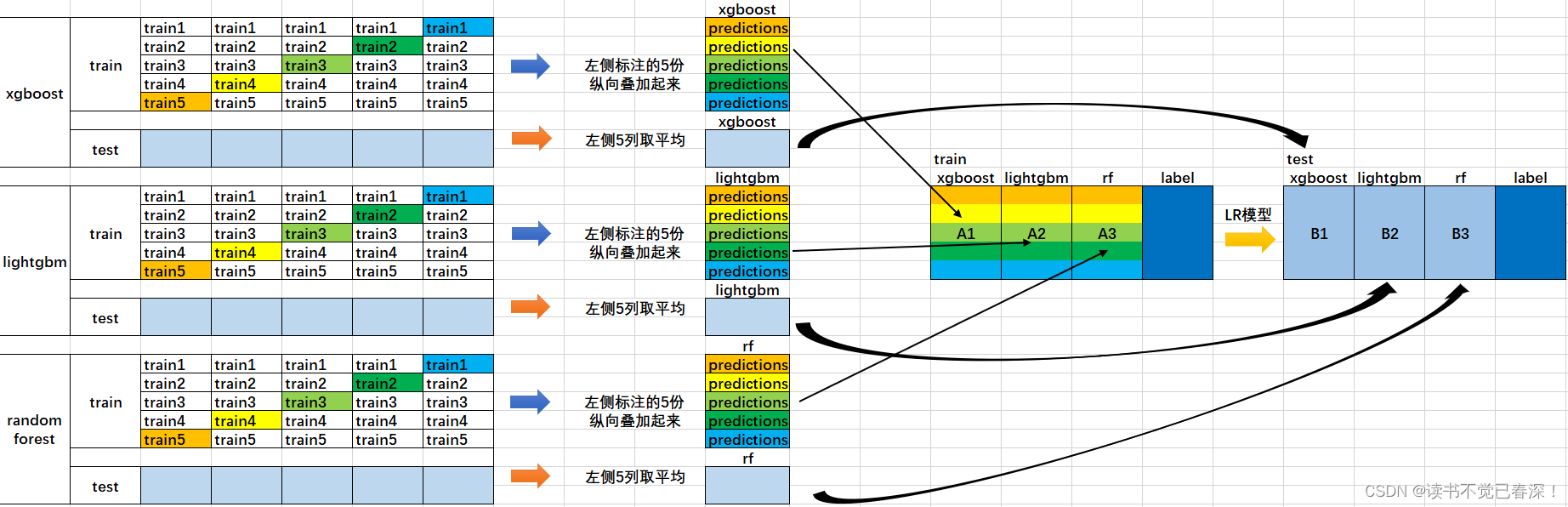
lending在集成的过程中只会用到验证集的数据,对数据实际上是一个很大的浪费,所以考虑交叉验证进行优化。
- 将所有数据集生成测试集和训练集(假如训练集为10000,测试集为2500行),那么上层会进行5折交叉检验(训练集8000条、验证集2000条)。
最后得到5×2000条验证集预测结果(橙色),5×2500条测试集的预测结果。 - 将验证集的预测结果拼接成10000×1的矩阵,标记为$A_1$,测试集预测结果进行加权平均,得到2500×1的矩阵,标记为$B_1$。
对3个基模型进行如上训练,得到了$A_1$、$A_2$、$A_3$、$B_1$、$B_2$、$B_3$六个矩阵。
将$A_1$、$A_2$、$A_3$并列为10000×3的矩阵作为training data,$B_1$、$B_2$、$B_3$合并在一起成2500×3的矩阵作为testing data,5次验证集标签作为标签进行训练。
- 预测testing data的结果为最终结果
2.4 Stacking算法案例
sklearn并没有直接对Stacking的方法,因此我们需要下载mlxtend工具包(pip install mlxtend)
StackingClassifier使用API和参数说明:
StackingClassifier(classifiers, meta_classifier, use_probas=False, average_probas=False, |
参数:
- classifiers : 基分类器,数组形式,[cl1, cl2, cl3]. 每个基分类器的属性被存储在类属性 self.clfs_.
- meta_classifier : 目标分类器,即将前面分类器合起来的分类器
- use_probas : bool (default: False) ,如果设置为True, 那么目标分类器的输入就是前面分类输出的类别概率值而不是类别标签
- average_probas : bool (default: False),当上一个参数use_probas = True时需设置
- average_probas=True表示所有基分类器输出的概率值需被平均,否则拼接。
- verbose : int, optional (default=0)。用来控制使用过程中的日志输出,当 verbose = 0时,什么也不输出, verbose = 1,输出回归器的序号和名字。verbose = 2,输出详细的参数信息。verbose > 2, 自动将verbose设置为小于2的,verbose -2.
- use_features_in_secondary : bool (default: False). 如果设置为True,那么最终的目标分类器就被基分类器产生的数据和最初的数据集同时训练。如果设置为False,最终的分类器只会使用基分类器产生的数据训练。
2.4.1 基分类器预测类别为特征
使用基分类器所产生的预测类别作为meta-classifier“特征”的输入数据# 1. 简单堆叠3折CV分类
from sklearn import datasets
iris = datasets.load_iris()
X, y = iris.data[:, 1:3], iris.target
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import StackingCVClassifier
RANDOM_SEED = 42
clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=RANDOM_SEED)
clf3 = GaussianNB()
lr = LogisticRegression()
# Starting from v0.16.0, StackingCVRegressor supports
# `random_state` to get deterministic result.
sclf = StackingCVClassifier(classifiers=[clf1, clf2, clf3], # 第一层分类器
meta_classifier=lr, # 第二层分类器
random_state=RANDOM_SEED)
print('3-fold cross validation:\n')
for clf, label in zip([clf1, clf2, clf3, sclf], ['KNN', 'Random Forest', 'Naive Bayes','StackingClassifier']):
scores = cross_val_score(clf, X, y, cv=3, scoring='accuracy')
print("Accuracy: %0.2f (+/- %0.2f) [%s]" % (scores.mean(), scores.std(), label))
3-fold cross validation: |
画出决策边界:from mlxtend.plotting import plot_decision_regions
import matplotlib.gridspec as gridspec
import itertools
gs = gridspec.GridSpec(2, 2)
fig = plt.figure(figsize=(10,8))
for clf, lab, grd in zip([clf1, clf2, clf3, sclf],
['KNN',
'Random Forest',
'Naive Bayes',
'StackingCVClassifier'],
itertools.product([0, 1], repeat=2)):
clf.fit(X, y)
ax = plt.subplot(gs[grd[0], grd[1]])
fig = plot_decision_regions(X=X, y=y, clf=clf)
plt.title(lab)
plt.show()
2.4.2 基分类器类别概率值为特征
使用第一层所有基分类器所产生的类别概率值作为meta-classfier的输入。需要在StackingClassifier 中增加一个参数设置:use_probas = True。
另外,还有一个参数设置average_probas = True,那么这些基分类器所产出的概率值将按照列被平均,否则会拼接。
- 基分类器1:predictions=[0.2,0.2,0.7]
- 基分类器2:predictions=[0.4,0.3,0.8]
- 基分类器3:predictions=[0.1,0.4,0.6]
若use_probas = True,average_probas = True,
产生的meta-feature 为:[0.233, 0.3, 0.7]
若use_probas = True,average_probas = False,
产生的meta-feature 为:[0.2,0.2,0.7,0.4,0.3,0.8,0.1,0.4,0.6]
# 2.使用概率作为元特征
clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
lr = LogisticRegression()
sclf = StackingCVClassifier(classifiers=[clf1, clf2, clf3],
use_probas=True, #
meta_classifier=lr,
random_state=42)
print('3-fold cross validation:\n')
for clf, label in zip([clf1, clf2, clf3, sclf],
['KNN',
'Random Forest',
'Naive Bayes',
'StackingClassifier']):
scores = cross_val_score(clf, X, y,
cv=3, scoring='accuracy')
print("Accuracy: %0.2f (+/- %0.2f) [%s]"
% (scores.mean(), scores.std(), label))
3-fold cross validation: |
2.4.3 基分类器使用部分特征
赋予不同的基分类器不同的特征。
比如:基分类器1训练前半部分的特征,基分类器2训练后半部分的特征。这部分的操作是通过sklearn中的pipelines实现。最终通过StackingClassifier组合起来。而不是给每一个基分类器全部的特征
# 3.在不同特征子集上运行的分类器的堆叠 |
2.4.4 结合网格搜索优化
# 4. 堆叠5折CV分类与网格搜索(结合网格搜索调参优化) |
0.947 +/- 0.03 {'kneighborsclassifier__n_neighbors': 1, 'meta_classifier__C': 0.1, 'randomforestclassifier__n_estimators': 10} |
2.4.5 绘制ROC曲线
- 像其他scikit-learn分类器一样,它StackingCVClassifier具有decision_function可用于绘制ROC曲线的方法。
- 请注意,decision_function期望并要求元分类器实现decision_function。
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import StackingCVClassifier
from sklearn.metrics import roc_curve, auc
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn.preprocessing import label_binarize
from sklearn.multiclass import OneVsRestClassifier
iris = datasets.load_iris()
X, y = iris.data[:, [0, 1]], iris.target
# Binarize the output
y = label_binarize(y, classes=[0, 1, 2])
n_classes = y.shape[1]
RANDOM_SEED = 42
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=RANDOM_SEED)
clf1 = LogisticRegression()
clf2 = RandomForestClassifier(random_state=RANDOM_SEED)
clf3 = SVC(random_state=RANDOM_SEED)
lr = LogisticRegression()
sclf = StackingCVClassifier(classifiers=[clf1, clf2, clf3],
meta_classifier=lr)
# Learn to predict each class against the other
classifier = OneVsRestClassifier(sclf)
y_score = classifier.fit(X_train, y_train).decision_function(X_test)
# Compute ROC curve and ROC area for each class
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(n_classes):
fpr[i], tpr[i], _ = roc_curve(y_test[:, i], y_score[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
# Compute micro-average ROC curve and ROC area
fpr["micro"], tpr["micro"], _ = roc_curve(y_test.ravel(), y_score.ravel())
roc_auc["micro"] = auc(fpr["micro"], tpr["micro"])
plt.figure()
lw = 2
plt.plot(fpr[2], tpr[2], color='darkorange',
lw=lw, label='ROC curve (area = %0.2f)' % roc_auc[2])
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic example')
plt.legend(loc="lower right")
plt.show()
2.4.6 Blending与Stacking对比
Blending的优点在于: - 比stacking简单(因为不用进行k次的交叉验证来获得stacker feature)
而缺点在于:
- 使用了很少的数据(是划分hold-out作为测试集,并非cv)
- blender可能会过拟合(其实大概率是第一点导致的)
- stacking使用多次的CV会比较稳健