
一、 Boosting算法原理
- Bagging:通过Bootstrap 的方式对全样本数据集进行抽样得到抽样子集,对不同的子集使用同一种基本模型进行拟合,然后投票得出最终的预测。
- Bagging主要通过降低方差的方式减少预测误差</font>
- Boosting:使用同一组数据集进行反复学习,得到一系列简单模型,然后组合这些模型构成一个预测性能十分强大的机器学习模型。
- Boosting通过不断减少偏差的形式提高最终的预测效果,与Bagging有着本质的不同。
在概率近似正确(PAC)学习的框架下:
- 弱学习:识别准确率略高于1/2(即准确率仅比随机猜测略高的学习算法)
- 强学习:识别准确率很高并能在多项式时间内完成的学习算法
- 强可学习和弱可学习是等价的,弱可学习算法,能提升至强可学习算法
- 提升方法:从弱学习算法出发,反复学习,得到一系列弱分类器(又称为基本分类器),再通过一定的形式去组合这些弱分类器构成一个强分类器。而弱可学习算法比强可学习算法容易得多。
- 大多数的Boosting方法都是通过改变训练数据集的概率分布(训练数据不同样本的权值),针对不同概率分布的数据调用弱分类算法学习一系列的弱分类器。
Boosting方法关键点:
- 每一轮学习应该如何改变数据的概率分布
- 如何将各个弱分类器组合起来
二、 Adaboost算法
2.1 Adaboost算法原理
Adaboost解决上述的两个问题的方式是:
- 提高那些被前一轮分类器错误分类的样本的权重</font>,而降低那些被正确分类的样本的权重。错误分类样本权重的增大而在后一轮的训练中“备受关注”。
- 各个弱分类器通过采取加权多数表决的方式组合</font>。分类错误率低的弱分类器权重高,分类错误率较大的弱分类器权重低。
Adaboost等Boosting模型增加了计算的复杂度和计算成本,用降低偏差的方式去减少总误差,但是过程中引入了方差,可能出现过拟合
Boosting方式无法做到现在流行的并行计算的方式进行训练,因为每一步迭代都要基于上一部的基本分类器。
- Adaboost算法是由基本分类器组成的加法模型,损失函数为指数损失函数。
Adaboost算法:
- 输入:二分类的训练数据集$T=\left{\left(x{1}, y{1}\right),\left(x{2}, y{2}\right), \cdots,\left(x{N}, y{N}\right)\right}$,特征$x{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}$,类别$y{i} \in \mathcal{Y}={-1,+1}$,$\mathcal{X}$是特征空间,$\mathcal{Y}$是类别集合,其中每个样本点由特征与类别组成。
- 输出:最终分类器$G(x)$。
(1) 初始化训练集样本的权值分布:其中权值是均匀分布,使得第一次没有先验信息的条件下每个样本在基本分类器的学习中作用一样。
(2) 对于学习轮次m=1,2,…,M
- 使用具有权值分布$Dm$的训练数据集进行学习,得到基本分类器:$G{m}(x): \mathcal{X} \rightarrow{-1,+1}$
- 计算$Gm(x)$在训练集上的分类误差率$$e{m}=\sum{i=1}^{N} P\left(G{m}\left(x{i}\right) \neq y{i}\right)=\sum{i=1}^{N} w{m i} I\left(G{m}\left(x{i}\right) \neq y{i}\right)$$
$w{m i}$代表了在$G_m(x)$中分类错误的样本权重和,这点直接说明了权重分布$D_m$与$G_m(x)$的分类错误率$e_m$有直接关系。 - 计算$Gm(x)$的系数$\alpha{m}=\frac{1}{2} \log \frac{1-e{m}}{e{m}}$,这里的log是自然对数ln
- $\alpha_{m}$表示了$G_m(x)$在最终分类器的重要性程度。
- 当$e{m} \leqslant \frac{1}{2}$时,$\alpha{m} \geqslant 0$,并且$\alpha_m$随着$e_m$的减少而增大,因此分类错误率越小的基本分类器在最终分类器的作用越大!
更新训练数据集的权重分布
这里的$Zm$是规范化因子,使得$D{m+1}$成为概率分布。
从上式可以看到:被基本分类器$Gm(x)$错误分类的样本的权重扩大,被正确分类的样本权重减少,二者相比相差$\mathrm{e}^{2 \alpha{m}}=\frac{1-e{m}}{e{m}}$倍。
(3) 构建基本分类器的线性组合$f(x)=\sum{m=1}^{M} \alpha{m} G_{m}(x)$,得到最终的分类器
线性组合$f(x)$实现了将M个基本分类器的加权表决,系数$\alpha_m$标志了基本分类器$G_m(x)$的重要性,值得注意的是:所有的$\alpha_m$之和不为1。$f(x)$的符号决定了样本x属于哪一类,其绝对值表示分类的确信度。
简单来说:计算M个基本分类器,每个分类器的错误率、模型权重及样本权重
- 均匀初始化样本权重$D_{1}$
- 对于轮次m,针对当前权重$D{m}$ 学习分类器 $G{m}(x)$,并计算其分类错误率$e_{m}$。
- 计算分类器$Gm(x)$的权重系数$\alpha{m}=\frac{1}{2} \log \frac{1-e{m}}{e{m}}$</font>。$e{m} \leqslant \frac{1}{2}$时,$\alpha{m} \geqslant 0$,并且$\alpha_m$随着$e_m$的减少而增大,因此分类错误率越小的基本分类器在最终分类器的作用越大!
- 更新权重分布
一般来说$\alpha{m} \geqslant 0,e^0=1$。被基本分类器$G_m(x)$错误分类的样本的权重扩大,被正确分类的样本权重减少。$e{m}$减小,$\alpha{m}$增大,${w{m+1, i}}$增大。即错误率越低的分类器,分类器权重和错误样本权重都越大,感觉上越准确准确的分类器学习力度越大。 - 基本分类器加权组合表决
- 总结:Adaboost不改变训练数据,而是改变其权值分布,使每一轮的基学习器学习不同权重分布的样本集,最后加权组合表决。
2.2 Adaboost算法举例
下面,我们使用一组简单的数据来手动计算Adaboost算法的过程:(例子来源http://www.csie.edu.tw)
训练数据如下表,假设基本分类器的形式是一个分割$x
解:
初始化样本权值分布
对m=1:
- 在权值分布$D_1$的训练数据集上,遍历每个结点并计算分类误差率$e_m$,阈值取v=2.5时分类误差率最低,那么基本分类器为:
- 样本7.8.9分错,$G1(x)$在训练数据集上的误差率为$e{1}=P\left(G{1}\left(x{i}\right) \neq y_{i}\right)=0.1*3=0.3$。
- 计算$G1(x)$的系数:$\alpha{1}=\frac{1}{2} \log \frac{1-e{1}}{e{1}}=0.4236$
- 更新训练数据的权值分布: 权重为[0.07143×7,0.16667×3]
对于m=2:
- 在权值分布$D_2$的训练数据集上,遍历每个结点并计算分类误差率$e_m$,阈值取v=8.5时分类误差率最低,那么基本分类器为:
- 样本4.5.6分错,$G_2(x)$在训练数据集上的误差率为$e_2 = 0.07143*3=0.2143$
- 计算$G_2(x)$的系数:$\alpha_2 = 0.6496$
- 更新训练数据的权值分布: 权重为[0.00455×4,0.1060×3,0.16667×3]。
- 对m=3:
- 在权值分布$D_3$的训练数据集上,遍历每个结点并计算分类误差率$e_m$,阈值取v=5.5时分类误差率最低,那么基本分类器为:
- 样本1.2.3.10分错,$G_3(x)$在训练数据集上的误差率为$e_3 =0.0455*4= 0.1820$
- 计算$G_3(x)$的系数:$\alpha_3 = 0.7514$
- 更新训练数据的权值分布:
$D_{4}=(0.125,0.125,0.125,0.102,0.102,0.102,0.065,0.065,0.065,0.125)$ 分类器$\operatorname{sign}\left[f{3}(x)\right]$在训练数据集上的误分类点的个数为0。
最终分类器为:$G(x)=\operatorname{sign}\left[f{3}(x)\right]=\operatorname{sign}\left[0.4236 G{1}(x)+0.6496 G{2}(x)+0.7514 G_{3}(x)\right]$
==可以看到每次样本权重和都为1,分类器错误率越来越低,分类器权重越来越高。最终分类器结果就是基分类器结果乘以其权重的加和==
2.3 Adaboos代码举例
数据集:CI的机器学习库里的葡萄酒数据集,该数据集包含了178个样本和13个特征,从不同的角度对不同的化学特性进行描述,最终预测红酒属于哪一个类别。(案例来源《python机器学习(第二版》)
# 引入数据科学相关工具包: |

下面对数据做简单解读:
Class label:分类标签
Alcohol:酒精
Malic acid:苹果酸
Ash:灰
Alcalinity of ash:灰的碱度
Magnesium:镁
Total phenols:总酚
Flavanoids:黄酮类化合物
Nonflavanoid phenols:非黄烷类酚类
Proanthocyanins:原花青素
Color intensity:色彩强度
Hue:色调
OD280/OD315 of diluted wines:稀释酒OD280 OD350
Proline:脯氨酸
# 数据预处理 |
# 使用单一决策树建模 |
# 使用sklearn实现Adaboost(基分类器为决策树) |
结果分析:单层决策树似乎对训练数据欠拟合,而Adaboost模型正确地预测了训练数据的所有分类标签,而且与单层决策树相比,Adaboost的测试性能也略有提高。然而,为什么模型在训练集和测试集的性能相差这么大呢?我们使用图像来简单说明下这个道理!
# 画出单层决策树与Adaboost的决策边界: |

从上面的决策边界图可以看到:
- Adaboost模型的决策边界比单层决策树的决策边界要复杂的多。也就是说,Adaboost试图用增加模型复杂度而降低偏差的方式去减少总误差,但是过程中引入了方差,可能出现过拟合
- 与单个分类器相比,Adaboost等Boosting模型增加了计算的复杂度,在实践中需要仔细思考是否愿意为预测性能的相对改善而增加计算成本
- Boosting方式无法做到现在流行的并行计算的方式进行训练,因为每一步迭代都要基于上一部的基本分类器。
三、 前向分步算法
Adaboost的算法内容:通过计算M个基本分类器,每个分类器的错误率、样本权重以及模型权重。我们可以认为:Adaboost每次学习单一分类器以及单一分类器的参数(权重)。
抽象出Adaboost算法的整体框架逻辑,构建集成学习的一个非常重要的框架——前向分步算法,有了这个框架,我们不仅可以解决分类问题,也可以解决回归问题。
3.1加法模型
在Adaboost模型中,我们把每个基本分类器合成一个复杂分类器的方法是每个基本分类器的加权和,即:$f(x)=\sum{m=1}^{M} \beta{m} b\left(x ; \gamma{m}\right)$,其中,$b\left(x ; \gamma{m}\right)$为即基本分类器,$\gamma{m}$为基本分类器的参数,$\beta_m$为基本分类器的权重,显然这与第二章所学的加法模型。为什么这么说呢?大家把$b(x ; \gamma{m})$看成是即函数即可。
在给定训练数据以及损失函数$L(y, f(x))$的条件下,学习加法模型$f(x)$就是:
通常这是一个复杂的优化问题,很难通过简单的凸优化的相关知识进行解决。前向分步算法可以用来求解这种方式的问题,它的基本思路是:因为学习的是加法模型,如果从前向后,每一步只优化一个基函数及其系数,逐步逼近目标函数,那么就可以降低优化的复杂度。具体而言,每一步只需要优化:
3.2 前向分步算法
给定数据集$T=\left{\left(x{1}, y{1}\right),\left(x{2}, y{2}\right), \cdots,\left(x{N}, y{N}\right)\right}$,$x{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}$,$y{i} \in \mathcal{Y}={+1,-1}$。损失函数$L(y, f(x))$,基函数集合${b(x ; \gamma)}$,我们需要输出加法模型$f(x)$。
- 初始化:$f_{0}(x)=0$
- 对m = 1,2,…,M:
- (a) 极小化损失函数:得到参数$\beta{m}$与$\gamma{m}$
- (b) 更新:
- 得到加法模型:
这样,前向分步算法将同时求解从m=1到M的所有参数$\beta{m}$,$\gamma{m}$的优化问题简化为逐次求解各个$\beta{m}$,$\gamma{m}$的问题。
3.3 前向分步算法与Adaboost的关系
由于这里不是我们的重点,我们主要阐述这里的结论,不做相关证明,具体的证明见李航老师的《统计学习方法》第八章的3.2节。Adaboost算法是前向分步算法的特例,Adaboost算法是由基本分类器组成的加法模型,损失函数为指数损失函数。
四、梯度提升决策树(GBDT)
- GBDT 的全称是 Gradient Boosting Decision Tree,梯度提升树。GBDT使用的决策树是CART回归树。为什么不用CART分类树呢?因为GBDT每次迭代要拟合的是梯度值,是连续值所以要用回归树
- CART假设决策树都是二叉树,内部节点特征取值为“是”和“否”,等价于递归二分每个特征。对回归树用平方误差最小化准则(回归树中的样本标签是连续数值,所以再使用熵之类的指标不再合适),对分类树用基尼系数最小化准则,进行特征选择生成二叉树
回归问题没有分类错误率可言,,用每个样本的残差表示每次使用基函数预测时没有解决的那部分问题
4.1 Decision Tree:CART回归树
最小二乘回归树生成算法见《统计学习方法》P82,算法5.5:

4.2 回归提升树算法
提升法:加法模型+前向分步算法。
提升树:以决策树为基函数(基本分类器)的提升方法,可表示为决策树的加法模型。
决策树:分类问题是二叉分类树,回归问题是二叉回归树Adaboost:加法模型+前向分步算法的分类树模型
- GBDT: 加法模型+前向分步算法的回归树模型
分类误差率
- Adaboost算法:使用了分类错误率修正样本权重以及计算每个基本分类器的权重
- GBDT:回归问题没有分类错误率可言,,用每个样本的残差表示每次使用基函数预测时没有解决的那部分问题
根据以上两点得到回归问题提升树算法:
输入:数据集$T=\left{\left(x{1}, y{1}\right),\left(x{2}, y{2}\right), \cdots,\left(x{N}, y{N}\right)\right}, x{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}, y{i} \in \mathcal{Y} \subseteq \mathbf{R}$
输出:最终的提升树$f_{M}(x)$
- 初始化$f_0(x) = 0$
- 对m = 1,2,…,M:
- 计算每个样本的残差:$r{m i}=y{i}-f{m-1}\left(x{i}\right), \quad i=1,2, \cdots, N$
- 拟合残差$r{mi}$学习一棵回归树,得到$T\left(x ; \Theta{m}\right)$
- 更新$f{m}(x)=f{m-1}(x)+T\left(x ; \Theta_{m}\right)$
- 得到最终的回归问题的提升树:$f{M}(x)=\sum{m=1}^{M} T\left(x ; \Theta_{m}\right)$
下面我们用一个实际的案例来使用这个算法:(案例来源:李航老师《统计学习方法》P168,此处省略)
4.3 梯度提升决策树算法(GBDT)
GBDT:利用损失函数的负梯度作为回归问题提升树算法中的残差的近似值,拟合回归树。
- 提升树利用加法模型和前向分步算法实现学习的过程,当损失函数为平方损失和指数损失时,每一步优化是相当简单的,也就是我们前面探讨的提升树算法和Adaboost算法。对于一般的损失函数而言,往往每一步的优化不是那么容易
- 针对这一问题,Freidman提出了梯度提升算法(gradient boosting),利用损失函数的负梯度在当前模型的值$-\left[\frac{\partial L\left(y, f\left(x{i}\right)\right)}{\partial f\left(x{i}\right)}\right]{f(x)=f{m-1}(x)}$作为回归问题提升树算法中的残差的近似值,拟合回归树。与其说负梯度作为残差的近似值,不如说残差是负梯度的一种特例。
以下开始具体介绍梯度提升算法:
输入训练数据集$T=\left{\left(x{1}, y{1}\right),\left(x{2}, y{2}\right), \cdots,\left(x{N}, y{N}\right)\right}, x{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}, y{i} \in \mathcal{Y} \subseteq \mathbf{R}$和损失函数$L(y, f(x))$,输出回归树$\hat{f}(x)$
- 初始化$f{0}(x)=\arg \min {c} \sum{i=1}^{N} L\left(y{i}, c\right)$
- 对于m=1,2,…,M:
- 对i = 1,2,…,N计算:$r{m i}=-\left[\frac{\partial L\left(y{i}, f\left(x{i}\right)\right)}{\partial f\left(x{i}\right)}\right]{f(x)=f{m-1}(x)}$
- 对$r{mi}$拟合一个回归树,得到第m棵树的叶结点区域$R{m j}, j=1,2, \cdots, J$
- 对j=1,2,…J,计算:$c{m j}=\arg \min {c} \sum{x{i} \in R{m j}} L\left(y{i}, f{m-1}\left(x{i}\right)+c\right)$
- 更新$f{m}(x)=f{m-1}(x)+\sum{j=1}^{J} c{m j} I\left(x \in R_{m j}\right)$
- 得到回归树:$\hat{f}(x)=f{M}(x)=\sum{m=1}^{M} \sum{j=1}^{J} c{m j} I\left(x \in R_{m j}\right)$
下面,我们来使用一个具体的案例来说明GBDT是如何运作的(案例来源 ):
下面的表格是数据:![\[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hBCnWMyY-1638484890166)(./6.png)\]](https://img-blog.csdnimg.cn/14f12b8bf27d43ad90e52d67258a25b0.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56We5rSb5Y2O,size_20,color_FFFFFF,t_70,g_se,x_16)
学习率:learning_rate=0.1,迭代次数:n_trees=5,树的深度:max_depth=3
平方损失的负梯度为:
$c=(1.1+1.3+1.7+1.8)/4=1.475,f_{0}(x)=c=1.475$
学习决策树,分裂结点:

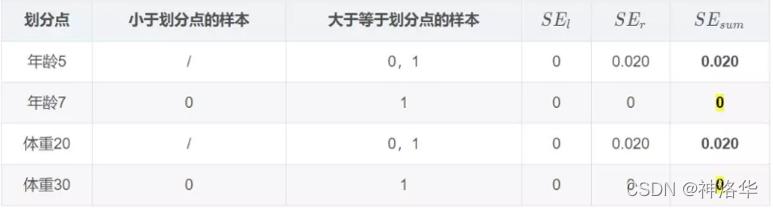
对于右节点,只有2,3两个样本,那么根据下表我们选择年龄30进行划分: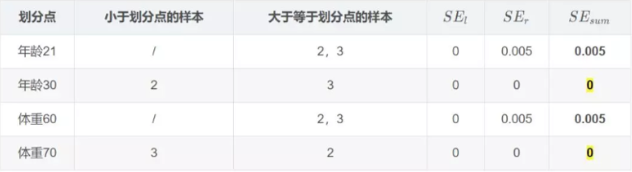
![\[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DgdpHG6v-1638484890170)(./13.png)\]](https://img-blog.csdnimg.cn/cce3670868d54729933a6769d75f6a29.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56We5rSb5Y2O,size_20,color_FFFFFF,t_70,g_se,x_16)
因此根据$\Upsilon{j 1}=\underbrace{\arg \min }{\Upsilon} \sum{x{i} \in R{j 1}} L\left(y{i}, f{0}\left(x{i}\right)+\Upsilon\right)$:
这里其实和上面初始化学习器是一个道理,平方损失,求导,令导数等于零,化简之后得到每个叶子节点的参数$\Upsilon$,其实就是标签值的均值。
最后得到五轮迭代: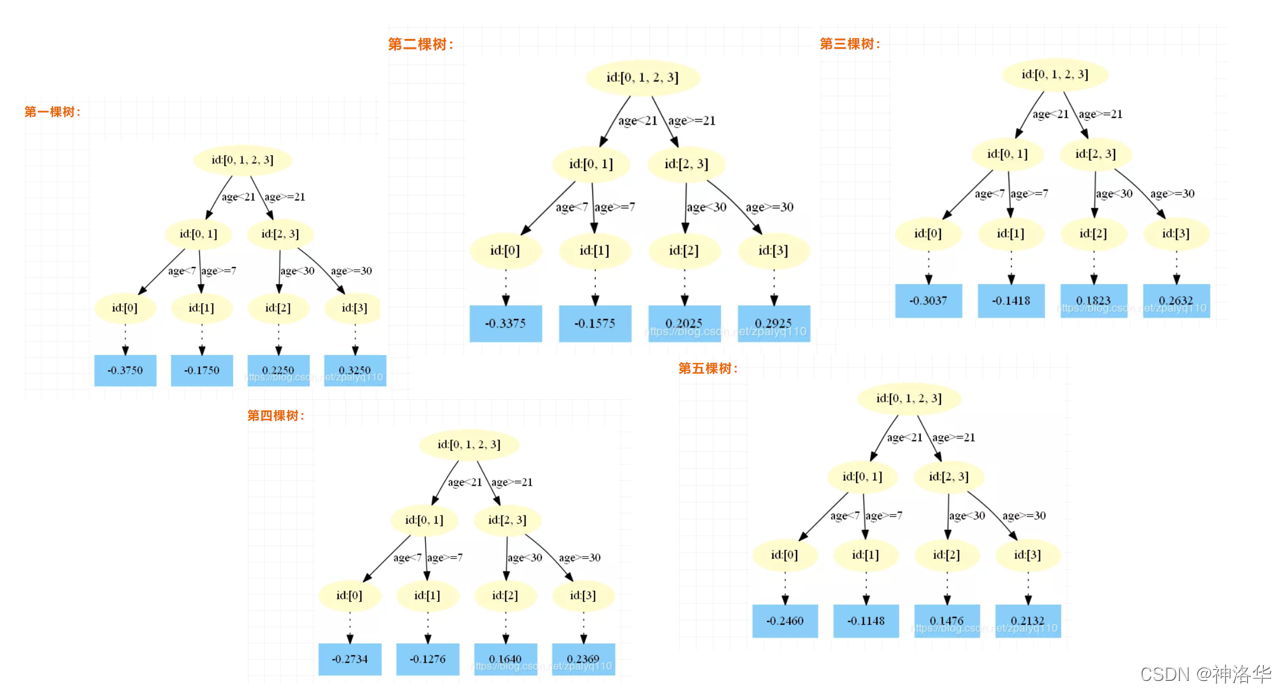
最后的强学习器为:$f(x)=f{5}(x)=f{0}(x)+\sum{m=1}^{5} \sum{j=1}^{4} \Upsilon{j m} I\left(x \in R{j m}\right)$。
其中:
预测结果为:
为什么要用学习率呢?这是Shrinkage的思想,如果每次都全部加上(学习率为1)很容易一步学到位导致过拟合。
4.3 GBDT代码示例
下面我们来使用sklearn来使用GBDT |
from sklearn.datasets import make_regression |
GradientBoostingRegressor与GradientBoostingClassifier函数的各个参数的意思!参考文档:
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingRegressor.html#sklearn.ensemble.GradientBoostingRegressor
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingClassifier.html?highlight=gra#sklearn.ensemble.GradientBoostingClassifier