
@[toc]
参考:Mysql基础.md
本项目来自《fun-rec/docs/第二章 推荐系统实战/2.2新闻推荐系统实战/》
【交流分享-腾讯微云】
vim /etc/resolv.conf |
mysql命令
systemctl start mysqld#启动mysql
systemctl status mysqld.service#查看mysql状态,running就是启动中
systemctl stop mysqld.service#关闭mysql服务
mysql -u root -p #登录mysql
grep "password" /var/log/mysqld.log#查看密码,直接复制登录
netstat -nlp #查看是否映射成功安装成功后没有mysql服务报错 没有此服务
我们应该找到 自己的mysq安装文件夹(博主的mysql在“ /home/tool/mysql_5.7.22”)
将/home/tool/mysql_5.7.22/support-files/mysql.server 拷贝到 /etc/init.d/mysqlmongodb命令:
- 添加路径:
export PATH=/usr/local/mongodb/bin:$PATH - 启动mongo服务:
mongod --dbpath /var/lib/mongo --logpath /var/log/mongodb/mongod.log --fork - 通过 ps ax | grep mongod查看数据库启动情况,如下图表示启动成功:
- 关闭mongodb服务通过ps ax | grep mongod命令查看mongodb运行的id
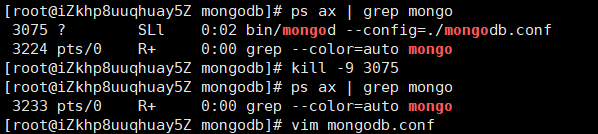
然后输入kill -9 进程id,杀死mongodb服务,如上图执行命令
- redis命令
systemctl start redis.service #启动redis服务 |
一、Mysql用户
启动MySQL/重启
[root@master software]# service mysql start |
#用户登录 |
# 创建用户 |
监听不到mysql端口查看帖子。
即之前为了免密登陆在vi /etc/my.cnf打开mysql设置文件,在最后一行加了skip-grant-tables或skip-network导致3306端口无法被监听到。注释掉这句话之后重启mysql服务就行。
二、Mysql-数据库
| 命令 | 作用 |
|---|---|
| CREATE DATABASE [IF NOT EXISTS] <数据库名称>; | 查看数据库。IF NOT EXISTS(可选项)避免数据库重名 |
| SHOW DATABASES [LIKE ‘数据库名’];; | 查看所有存在的数据库 |
| USE <数据库名> | 选择数据库 |
| DROP DATABASE [IF EXISTS] <数据库名> | 删除数据库 |
|
三、Mysql-表的基本操作
3.1 表的创建和修改
创建表的语法结构如下:
CREATE TABLE <表名> (<字段1> <数据类型> <该列所需约束>, |
-- 创建一个名为Product的表 |
| 命令 | 作用 |
|---|---|
| DESC Product; | 查询表product |
| DROP TABLE <表名>; | 删除表,无法恢复 |
| rename命令:ALTER TABLE Student RENAME Students; | 更新表名Student => Students。 |
| add命令:ALTER TABLE Students ADD sex CHAR(1), ADD age INT; | 插入字段,用逗号隔开 |
| drop命令:ALTER TABLE Students DROP stu_num; | 删除字段 |
| modify命令:ALTER TABLE Students MODIFY age CHAR(3); | 修改字段类型 |
| change:ALTER TABLE Students CHANGE name stu_name CHAR(12); | 修改字段名name =>stu_name,数据类型改为CHAR(12)。 |
-- 通过FIRST在表首插入字段stu_num |
3.2 表的查询
3.2. 1. SELECT语句查询和算式运算
SELECT <字段名>, …… |
- 通过AS语句对展示的字段另起别名,这不会修改表内字段的名字:
- 设定汉语别名时需要使用双引号(”)括起来,英文字符则不需要:
SELECT |
可以在SELECT语句中使用计算表达式:SELECT
product_name,
sale_price,
sale_price * 2 AS "sale_price_x2"
FROM Product;
-- 结果如下
+--------------+------------+---------------+
| product_name | sale_price | sale_price_x2 |
+--------------+------------+---------------+
| T恤衫 | 1000 | 2000 |
| 打孔器 | 500 | 1000 |
| 运动T恤 | 4000 | 8000 |
| 菜刀 | 3000 | 6000 |
| 高压锅 | 6800 | 13600 |
| 叉子 | 500 | 1000 |
| 擦菜板 | 880 | 1760 |
| 圆珠笔 | 100 | 200 |
+--------------+------------+---------------+
- 常数的查询:SELECT子句中,除了可以写字段外,还可以写常数。即将查询的字段填入常数
SELECT |
- 去重:在SELECT语句中使用DISTINCT可以去除重复行。
NULL 也被视为一类数据。NULL 存在于多行中时,会被合并为一条NULL 数据。
mysql> SELECT |
多个字段组合删除:SELECT
DISTINCT product_type, regist_date
FROM Product;
#(删除product_type, regist_date都重复的商品)
3.2.6 指定查询和比较运算符
SELECT <字段名>, …… |
例如:
SELECT product_name |
- WHERE 子句中通过使用比较运算符可以组合出各种各样的条件表达式。(><=等等)不能对NULL使用任何比较运算符,只能通过IS NULL、IS NOT NULL语句来判断
字符串比较:按照字典顺序进行比较,也就是像姓名那样,按照条目在字典中出现的顺序来进行排序。例如:
'1' < '10' < '11' < '2' < '222' < '3'
也可以使用逻辑运算符AND OR NOT。NULL和任何值做逻辑运算结果都是不确定(第三种真值UNKNOWN)。因此尽量给字段加上NOT NULL的约束。
SELECT product_type, sale_price |
3.3 表的复制
| 命令 | 作用 |
|---|---|
| CREATE TABLE Product_COPY1 SELECT * FROM Product; | 从product表复制表Product_COPY1 |
| CREATE TABLE Product_COPY1 LIKe Product; | 通过LIKE复制表结构 |
四、Mysql-分组查询
4.1 聚合函数
通过 SQL 对数据进行某种操作或计算时需要使用函数。
- COUNT:计算表中的记录数(行数)
- SUM: 计算表中数值列中数据的合计值
- AVG: 计算表中数值列中数据的平均值
- MAX: 求出表中任意列中数据的最大值
- MIN: 求出表中任意列中数据的最小值
SELECT COUNT(*) FROM Product;#其它的函数均不可以将*作为参数 |
- MAX/MIN函数几乎适用于所有数据类型的列,包括字符和日期。SUM/AVG函数只适用于数值类型的列。
- 在聚合函数删除重复值,DISTINCT必须写在括号中。这是因为必须要在计算行数之前删除 product_type 字段中的重复数据。
SELECT COUNT(DISTINCT product_type) |
4.2 对表分组
类似pandas的group by语句,也是group by分组,语法结构如下:
SELECT <列名1>, <列名2>, <列名3>, …… |
SELECT product_type, COUNT(*) |
在该语句中,我们首先通过GROUP BY函数对指定的字段product_type进行分组。分组时,product_type字段中具有相同值的行会汇聚到同一组。
最后通过COUNT函数,统计不同分组的包含的行数。
- NULL的数据会被聚合为一组。
- 语句顺序:1. SELECT → 2. FROM → 3. WHERE → 4. GROUP BY
windows下安装PyMySQL:python -m pip install PyMySQL
centos安装: pip install PyMySQL
五、redis安装连接
redis安装地址:官网,选择安装5.0.14。
参考文章《CentOS 7安装Redis5.0.7》、《Centos7安装Redis》
- 解压安装
解压:tar -zxvf redis-5.0.14.tar.gz
进入目录后安装:cd redis-5.0.14
先运行:make
然后指定目录安装:make install PREFIX=/usr/local/redis
第一次只编译了一次,没有redis -cli命令
==后来liunx系统时间不对。本地时间2021-12-14,liunx时间是2021-7-20。编译显示创建不完整,也是错误。==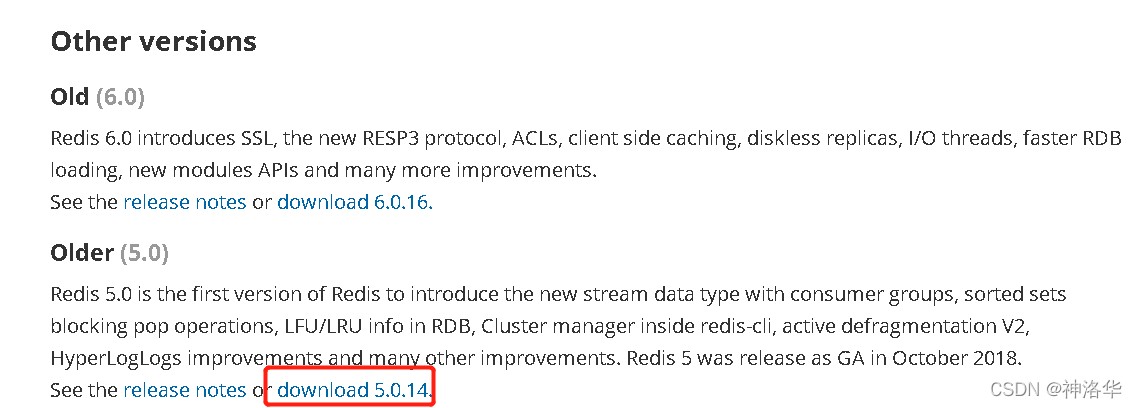
- 前台启动
[root@localhost redis-5.0.3]# cd /usr/local/redis/bin/
[root@localhost bin]# ./redis-server
启动后如图所示:
==前台启动的时候exit没退出直接ctrl+z强行退出,结果其实redis服务一直没退,后面systemctl start redis.service、systemctl status redis.service一直显示redis状态没开,端口被占用。xshell重现连接才好的。==
- 后台启动
从 redis 的源码目录中复制 redis.conf 到 redis 的安装目录
[root@localhost bin]# cp /usr/local/redis-5.0.3/redis.conf /usr/local/redis/bin/
修改安装目录/usr/local/redis/bin/下的redis.conf配置文件:vim redis.conf
修改以下配置:
#bind 127.0.0.1 # 将这行代码注释,监听所有的ip地址,外网可以访问 |

- 设置开机启动
添加开机启动服务[root@localhost bin]# vi /etc/systemd/system/redis.service
[Unit] |
- 设置开机启动其它服务操作命令:
[root@localhost bin]# systemctl daemon-reload
[root@localhost bin]# systemctl start redis.service
[root@localhost bin]# systemctl enable redis.servicesystemctl start redis.service #启动redis服务
systemctl stop redis.service #停止redis服务
systemctl restart redis.service #重新启动服务
systemctl status redis.service #查看服务当前状态
systemctl enable redis.service #设置开机自启动
systemctl disable redis.service #停止开机自启动 创建 redis 命令软链接:
[root@localhost ~]# ln -s /usr/local/redis/bin/redis-cli /usr/bin/redis连接 redis并退出:(按上面走完就ok了。不知道为啥redis -cli不行)
[root@192 bin]# redis
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> quit
[root@192 bin]#- redis-cli 未找到命令的一个解决方式
将redis解压后的安装文件redis-5.0.14下src目录里的redis-cli文件,复制到/usr/local/bin/路径中
[root@localhost redis-5.0.14]# cp src/redis-cli /usr/local/bin/
现在就可以执行redis-cli命令了。
六、redis操作命令
具体操作参考《Redis基础.md》
- EXPIRE key_name seconds :多少秒后名为key_name的key自动删除。key存在返回1,否则返回0。
127.0.0.1:6378> set key1 “value”:string类型的key
127.0.0.1:6378> lpush key2 “value”:list类型key
127.0.0.1:6378> SADD key3 “value”:set类型key - DEL key:删除key,可以是列表
- TYPE key:查看key的类型
Python调用Redis:
windows下安装redis库:python -m pip install redis
centos下安装:pip install redis
七、MongoDB
7.1 安装MongoDB
先安装libcurl 和openssl。
- yum命令出现Loaded plugins: fastestmirror Determining fastest mirrors 在进行yum安装的时候报错。参考此文进行修改。
- [Errno 14] curl#6 - “Could not resolve host: mirrors.163.com; Unknown error“。参考此文
然后直接yum install libcurl yum install openssl
一开始两个显示网站下载太慢尝试其它镜像,第三个网站顺利下载了。
at /etc/issue 查看centos版本。然后在官网下载。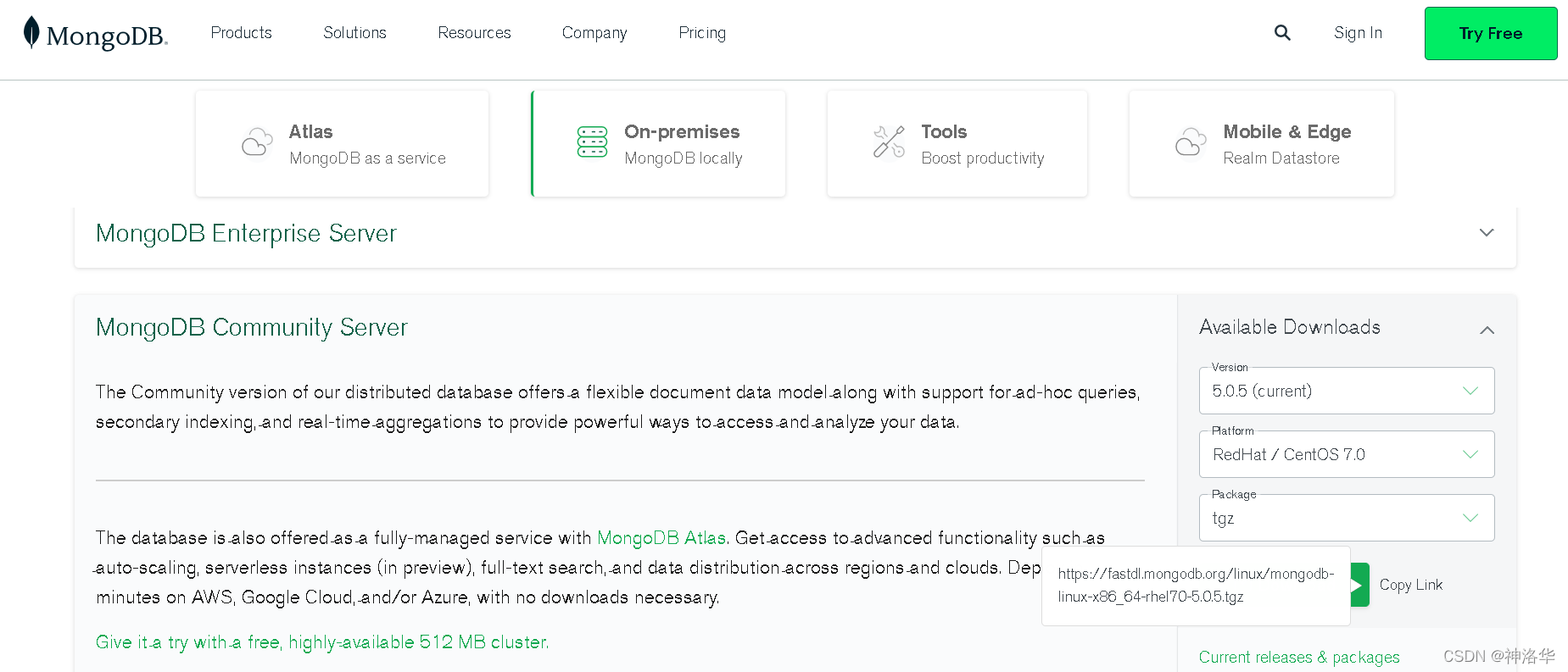
copy链接之后:wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-5.0.5.tgz
解压:tar -zxvf mongodb-linux-x86_64-rhel70-5.0.5.tgz
重命名mv mongodb-linux-x86_64-rhel70-5.0.5 mongodb-5
可以将MongoDB 的可执行文件(bin目录下)添加到 PATH 路径中export PATH=/usr/local/mongodb/bin:$PATH(这步貌似是临时的,但是不执行mongod命令无法执行)
配置MongoDB,编辑etc下的profile文件,加入一句指令:export PATH=$PATH:/usr/local/mongodb-5/bin。配置完保存,之后将CentOS7关机重启。
创建数据存储目录:mkdir -p /var/lib/mongo
创建日志目录:mkdir -p /var/log/mongodb
启动mongo服务:mongod --dbpath /var/lib/mongo --logpath /var/log/mongodb/mongod.log --fork
通过 ps ax | grep mongod查看数据库启动情况,如下图表示启动成功:
在usr/mongodb目录下新建一个名为mongodb.conf的配置文件,写入如下配置内容(不能有中文):
port=27017 |
保存。然后输入命令启动mongod --config /usr/local/mongodb-5/mongodb.conf
关闭mongodb服务通过ps ax | grep mongod命令查看mongodb运行的id
然后输入kill -9 进程id,杀死mongodb服务,如上图执行命令
保存。然后输入命令启动mongod —config /usr/local/mongodb-5/mongodb.conf
7.2 Mongodb操作
7.2.1 数据库

- “show dbs” :显示所有数据的列表。
- “db” :显示当前数据库对象或集合。
- “use”:连接到一个指定的数据库。
- use 数据库名:创建数据库。刚创建的数据库 tobytest并不在数据库的列表中,需要插入数据。
- db.tobytest.insert({“name”:”Toby”}):向数据库插入数据
7.2.2 创建集合
db.createCollection(name, options):创建集合show collections 或 show tables:查看集合db.collection.drop():删除集合
name: 要创建的集合名称
options: 可选参数, 指定有关内存大小及索引的选项
例如:
db.createCollection("tobycollection") |
7.2.3 插入文档
db.COLLECTION_NAME.insert(document):插入文档db.COLLECTION_NAME.save(document):插入文档
- save():如果 _id 主键存在则更新数据,如果不存在就插入数据。该方法新版本中已废弃,可以使用 db.collection.insertOne() 或 db.collection.replaceOne() 来代替。
- insert(): 若插入的数据主键已经存在,则会抛 org.springframework.dao.DuplicateKeyException 异常,提示主键重复,不保存当前数据。
db.col.insert({title:'Toby MongoDB', |
- 更新文档
- 删除文档
- 查询文档
- 排序
7.3 Python MongoDB
Python 要连接 MongoDB 需要 MongoDB 驱动,这里我们使用 PyMongo 驱动来连接。
安装:pip install pymongo
用vim打开一个空白文档,然后把已经复制的代码给粘贴进来,发现它有自动缩进功能,最终导致粘贴的文本一行比一行靠右,看起来乱成一团。比较快的解决办法是,在粘贴文档前,在命令行模式下,输入::set paste
编辑完后输入::set nopaste
八、scrapy
按照教程写的编辑好那些文件之后执行sh runscrapy_sina.sh报错:
参考:[帖子](https://blog.csdn.net/lmhlmh/article/details/107135295?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522163950211916780271576675%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=163950211916780271576675&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-2-107135295.pc_search_insert_es_download_v2&utm_term=Unknown%20command:%20crawl&spm=1018.2226.3001.4187)Scrapy 2.5.1 - no active project
Unknown command: crawlno active project:说明我的工程有问题。
于是去看了看目录结构。查了下手册。在使用命令行startproject的时候,会自动生成scrapy.cfg
问题就出在这里,别人的项目文件中只有代码,没有配置文件,于是自己找了一个配置文件scrapy.cfg
- No module named ‘pymongo‘
- 这是因为我的centos有python2和3两个版本。执行py文件的时候要写python3 xx.py。而教程里面都是直接写python。
- 改动成python就可以执行python3操作:
- cd /usr/bin
- 备份原路径:mv python python.bak
- python 链接到python3 :ln -s python3 python
- 查看版本:python -V现在显示python3而不是2了
- 修改yum配置文件(yum要使用python2才可以运行)vim向下删除到文档结尾:dG
#以下两个配置文件最顶部的\#!/usr/bin/python修改为 #!/usr/bin/python2
vim /usr/bin/yum
vim /usr/libexec/urlgrabber-ext-down
运行 sh run_scrapy_sina.sh显示没有库sinanews,将monitor_news.py的from sinanews.settings import MONGO_HOST, MONGO_PORT, DB_NAME, COLLECTION_NAME前面的sinanews.删除。