
@[toc]
参考
- 《算法通关手册》-哈希表篇
- 【博文】散列表(上)- 数据结构与算法之美 - 极客时间
一、哈希表
1.1 哈希表简介
哈希表(Hash Table):也叫做散列表。是根据关键码值(Key Value)直接进行访问的数据结构。
哈希表通过「键 key 」和「映射函数 Hash(key) 」计算出对应的「值 value」,把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做「哈希函数(散列函数)」,存放记录的数组叫做「哈希表(散列表)」。
哈希表的关键思想是使用哈希函数,将键 key 映射到对应表的某个区块中。我们可以将算法思想分为两个部分:
- 向哈希表中插入一个关键码值:哈希函数决定该关键字的对应值应该存放到表中的哪个区块,并将对应值存放到该区块中。
- 在哈希表中搜索一个关键码值:使用相同的哈希函数从哈希表中查找对应的区块,并在特定的区块搜索该关键字对应的值。
哈希表的原理示例图如下所示:
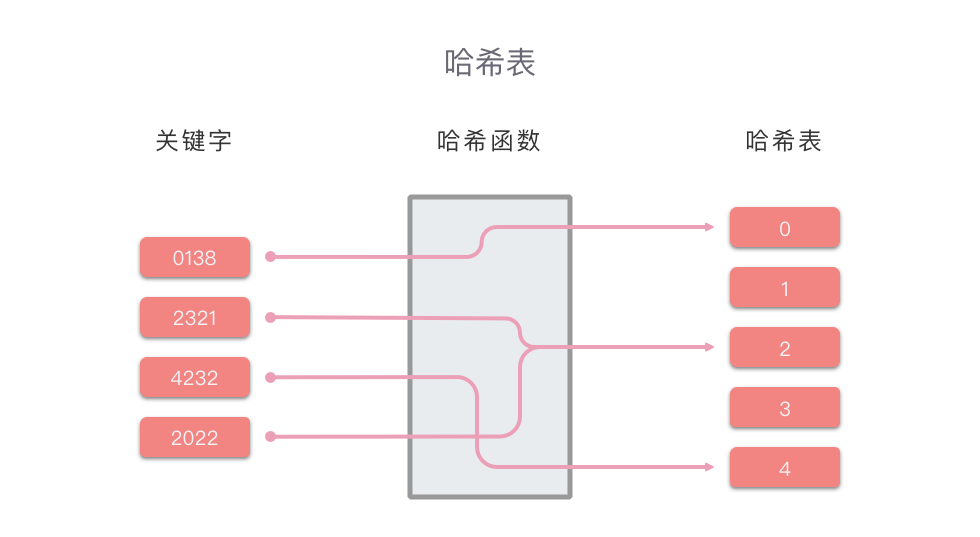
在上图例子中,我们使用 value = Hash(key) = key // 1000 作为哈希函数。// 符号代表整除。我们以这个例子来说明一下哈希表的插入和查找策略。
- 向哈希表中插入一个关键码值:通过哈希函数解析关键字,并将对应值存放到该区块中。
- 比如:
0138通过哈希函数Hash(key) = 0138 // 100 = 0,得出应将0138分配到0所在的区块中。
- 比如:
- 在哈希表中搜索一个关键码值:通过哈希函数解析关键字,并在特定的区块搜索该关键字对应的值。
- 比如:查找
2321,通过哈希函数,得出2321应该在2所对应的区块中。然后我们从2对应的区块中继续搜索,并在2对应的区块中成功找到了2321。 - 比如:查找
3214,通过哈希函数,得出3214应该在3所对应的区块中。然后我们从3对应的区块中继续搜索,但并没有找到对应值,则说明3214不在哈希表中。
- 比如:查找
哈希表在生活中的应用也很广泛,其中一个常见例子就是「查字典」。
比如为了查找 赞 这个字的具体意思,我们在字典中根据这个字的拼音索引 zan,查找到对应的页码为 599。然后我们就可以翻到字典的第 599 页查看 赞 字相关的解释了。
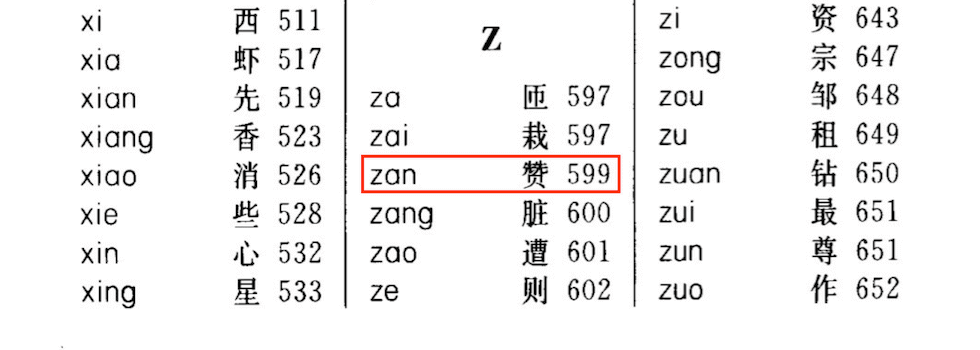
在这个例子中:
- 存放所有拼音和对应地址的表可以看做是 「哈希表」。
赞字的拼音索引zan可以看做是哈希表中的 「关键字key」。- 根据拼音索引
zan来确定字对应页码的过程可以看做是哈希表中的 「哈希函数Hash(key)」。 - 查找到的对应页码
599可以看做是哈希表中的 「哈希地址value」。
1.2 哈希函数
哈希函数(Hash Function):将哈希表中元素的关键键值映射为元素存储位置的函数。
哈希函数是哈希表中最重要的部分。一般来说,哈希函数会满足以下几个条件:
- 哈希函数应该易于计算,并且尽量使计算出来的索引值均匀分布。
- 哈希函数计算得到的哈希值是一个固定长度的输出值。
- 如果
Hash(key1)不等于Hash(key2),那么key1、key2一定不相等。 - 如果
Hash(key1)等于Hash(key2),那么key1、key2可能相等,也可能不相等(会发生哈希碰撞)。
在哈希表的实际应用中,关键字的类型除了数字类,还有可能是字符串类型、浮点数类型、大整数类型,甚至还有可能是几种类型的组合。一般我们会将各种类型的关键字先转换为整数类型,再通过哈希函数,将其映射到哈希表中。
而关于整数类型的关键字,通常用到的哈希函数方法有:直接定址法、除留余数法、平方取中法、基数转换法、数字分析法、折叠法、随机数法、乘积法、点积法等。下面我们介绍几个常用的哈希函数方法。
1.2.1 直接定址法
- 直接定址法:取关键字本身 / 关键字的某个线性函数值 作为哈希地址。即:
Hash(key) = key或者Hash(key) = a * key + b,其中a和b为常数。
这种方法计算最简单,且不会产生冲突。适合于关键字分布基本连续的情况,如果关键字分布不连续,空位较多,则会造成存储空间的浪费。
举一个例子,假设我们有一个记录了从 1 岁到 100 岁的人口数字统计表。其中年龄为关键字,哈希函数取关键字自身,如下表所示。
| 年龄 | 1 | 2 | 3 | … | 25 | 26 | 27 | … | 100 |
|---|---|---|---|---|---|---|---|---|---|
| 人数 | 3000 | 2000 | 5000 | … | 1050 | … | … | … | … |
比如我们想要查询 25 岁的人有多少,则只要查询表中第 25 项即可。
1.2.2 除留余数法
- 除留余数法:假设哈希表的表长为
m,取一个不大于m但接近或等于m的质数p,利用取模运算,将关键字转换为哈希地址。即:Hash(key) = key % p,其中p为不大于m的质数。
这也是一种简单且常用的哈希函数方法。其关键点在于 p 的选择。根据经验而言,一般 p 取素数或者 m,这样可以尽可能的减少冲突。
比如我们需要将 7 个数 [432, 5, 128, 193, 92, 111, 88] 存储在 11 个区块中(长度为 11 的数组),通过除留余数法将这 7 个数应分别位于如下地址:
| 索引 | 00 | 01 | 02 | 03 | 04 | 05 | 06 | 07 | 08 | 09 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 数据 | 88 | 111 | 432 | 92 | 5 | 193 | 128 |
1.2.3 平方取中法
- 平方取中法:先通过求关键字平方值的方式扩大相近数之间的差别,然后根据表长度取关键字平方值的中间几位数为哈希地址。
- 比如:
Hash(key) = (key * key) // 100 % 1000,先计算平方,去除末尾的 2 位数,再取中间 3 位数作为哈希地址。
- 比如:
这种方法因为关键字平方值的中间几位数和原关键字的每一位数都相关,所以产生的哈希地址也比较均匀,有利于减少冲突的发生。
2.4 基数转换法
- 基数转换法:将关键字看成另一种进制的数再转换成原来进制的数,然后选其中几位作为哈希地址。
- 比如,将关键字看做是
13进制的数,再将其转变为10进制的数,将其作为哈希地址。
- 比如,将关键字看做是
以 343246 为例,哈希地址计算方式如下:
$343246{13} = 3 \times 13^5 + 4 \times 13^4 + 3 \times 13^3 + 2 \times 13^2 + 4 \times 13^1 + 6 \times 13^0 = 1235110{10}$
1.3 哈希冲突
哈希冲突(Hash Collision):不同的关键字通过同一个哈希函数可能得到同一哈希地址,即
key1 ≠ key2,而Hash(key1) = Hash(key2),这种现象称为哈希冲突。
理想状态下,我们的哈希函数是完美的一对一映射,即一个关键字(key)对应一个值(value),不需要处理冲突。但是一般情况下,不同的关键字 key 可能对应了同一个值 value,这就发生了哈希冲突。
设计再好的哈希函数也无法完全避免哈希冲突。所以就需要通过一定的方法来解决哈希冲突问题。常用的哈希冲突解决方法主要是两类:「开放地址法(Open Addressing)」 和 「链地址法(Chaining)」。
1.3.1 开放地址法
开放地址法(Open Addressing):指的是将哈希表中的「空地址」向处理冲突开放。当哈希表未满时,处理冲突时需要尝试另外的单元,直到找到空的单元为止。
当发生冲突时,开放地址法按照下面的方法求得后继哈希地址:H(i) = (Hash(key) + F(i)) % m,i = 1, 2, 3, ..., n (n ≤ m - 1)。
H(i)是在处理冲突中得到的地址序列。即在第 1 次冲突(i = 1)时经过处理得到一个新地址H(1),如果在H(1)处仍然发生冲突(i = 2)时经过处理时得到另一个新地址H(2)…… 如此下去,直到求得的H(n)不再发生冲突。Hash(key)是哈希函数,m是哈希表表长,对哈希表长取余的目的是为了使得到的下一个地址一定落在哈希表中。F(i)是冲突解决方法,取法可以有以下几种:- 线性探测法:$F(i) = 1, 2, 3, …, m - 1$。
- 二次探测法:$F(i) = 1^2, -1^2, 2^2, -2^2, …, \pm n^2(n \le m / 2)$。
- 伪随机数序列:$F(i) = 伪随机数序列$。
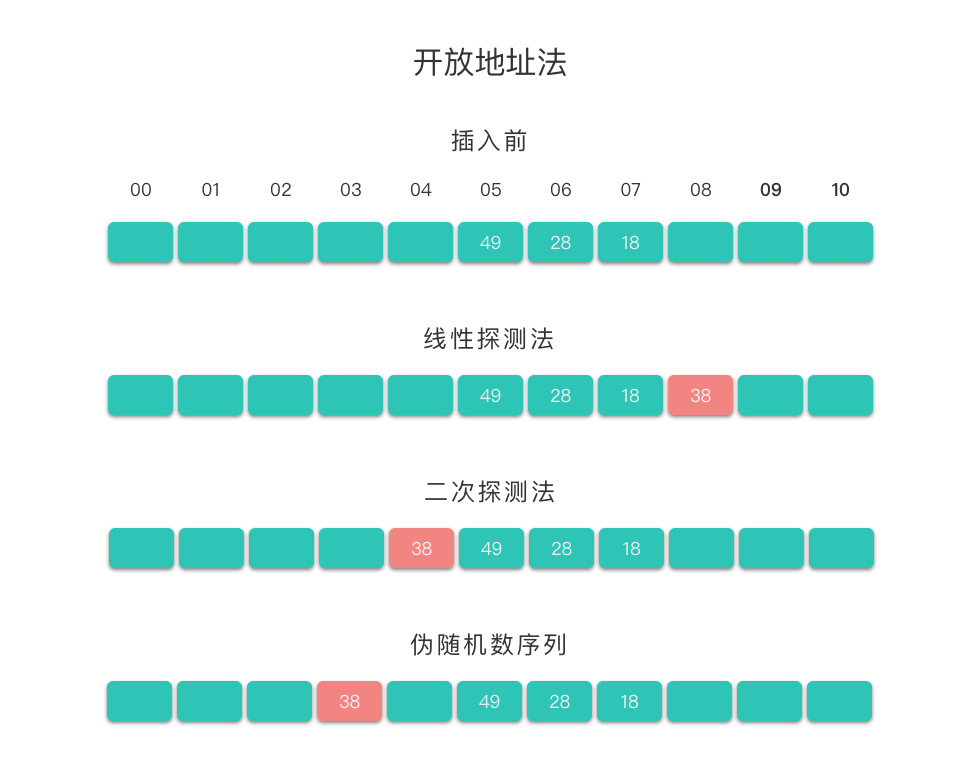
举个例子说说明一下如何用以上三种冲突解决方法处理冲突,并得到新地址 H(i)。例如,在长度为 11 的哈希表中已经填有关键字分别为 28、49、18 的记录(哈希函数为 Hash(key) = key % 11)。现在将插入关键字为 38 的新纪录。根据哈希函数得到的哈希地址为 5,产生冲突。接下来分别使用这三种冲突解决方法处理冲突。
- 使用线性探测法:得到下一个地址
H(1) = (5 + 1) % 11 = 6,仍然冲突;继续求出H(2) = (5 + 2) % 11 = 7,仍然冲突;继续求出H(3) = (5 + 3) % 11 = 8,8对应的地址为空,处理冲突过程结束,记录填入哈希表中序号为8的位置。 - 使用二次探测法:得到下一个地址
H(1) = (5 + 1*1) % 11 = 6,仍然冲突;继续求出H(2) = (5 - 1*1) % 11 = 4,4对应的地址为空,处理冲突过程结束,记录填入哈希表中序号为4的位置。 - 使用伪随机数序列:假设伪随机数为
9,则得到下一个地址H(1) = (9 + 5) % 11 = 3,3对应的地址为空,处理冲突过程结束,记录填入哈希表中序号为3的位置。
使用这三种方法处理冲突的结果如下图所示:
1.3.2 链地址法
链地址法(Chaining):将具有相同哈希地址的元素(或记录)存储在同一个线性链表中。
链地址法是一种更加常用的哈希冲突解决方法。相比于开放地址法,链地址法更加简单。
我们假设哈希函数产生的哈希地址区间为 [0, m - 1],哈希表的表长为 m。则可以将哈希表定义为一个有 m 个头节点组成的链表指针数组 T。
这样在插入关键字的时候,我们只需要通过哈希函数
Hash(key)计算出对应的哈希地址i,然后将其以链表节点的形式插入到以T[i]为头节点的单链表中。在链表中插入位置可以在表头或表尾,也可以在中间。如果每次插入位置为表头,则插入操作的时间复杂度为 $O(1)$。而在在查询关键字的时候,我们只需要通过哈希函数
Hash(key)计算出对应的哈希地址i,然后将对应位置上的链表整个扫描一遍,比较链表中每个链节点的键值与查询的键值是否一致。查询操作的时间复杂度跟链表的长度k成正比,也就是 $O(k)$。对于哈希地址比较均匀的哈希函数来说,理论上讲,k = n // m,其中n为关键字的个数,m为哈希表的表长。
举个例子来说明如何使用链地址法处理冲突。假设现在要存入的关键字集合 keys = [88, 60, 65, 69, 90, 39, 07, 06, 14, 44, 52, 70, 21, 45, 19, 32]。再假定哈希函数为 Hash(key) = key % 13,哈希表的表长 m = 13,哈希地址范围为 [0, m - 1]。将这些关键字使用链地址法处理冲突,并按顺序加入哈希表中(图示为插入链表表尾位置),最终得到的哈希表如下图所示。
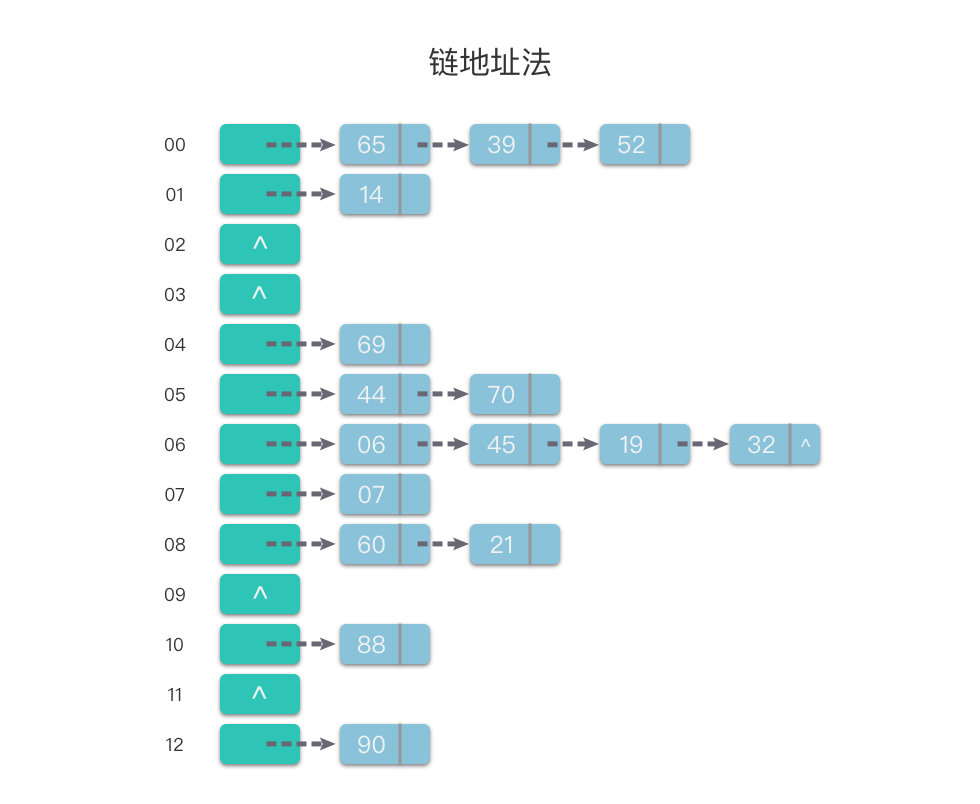
相对于开放地址法,采用链地址法处理冲突要多占用一些存储空间(主要是链节点占用空间)。但它可以减少在进行插入和查找具有相同哈希地址的关键字的操作过程中的平均查找长度。这是因为在链地址法中,待比较的关键字都是具有相同哈希地址的元素,而在开放地址法中,待比较的关键字不仅包含具有相同哈希地址的元素,而且还包含哈希地址不相同的元素。
1.4 哈希表总结
本文讲解了一些比较基础、偏理论的哈希表知识。包含哈希表的定义,哈希函数、哈希冲突以及哈希冲突的解决方法。
- 哈希表(Hash Table):通过键
key和一个映射函数Hash(key)计算出对应的值value,把关键码值映射到表中一个位置来访问记录,以加快查找的速度。 - 哈希函数(Hash Function):将哈希表中元素的关键键值映射为元素存储位置的函数。
- 哈希冲突(Hash Collision):不同的关键字通过同一个哈希函数可能得到同一哈希地址。
哈希表的两个核心问题是:「哈希函数的构建」 和 「哈希冲突的解决方法」。
- 常用的哈希函数方法有:直接定址法、除留余数法、平方取中法、基数转换法、数字分析法、折叠法、随机数法、乘积法、点积法等。
- 常用的哈希冲突的解决方法有两种:开放地址法和链地址法。
二、哈希表应用
2.1 哈希表题目列表
| 题号 | 标题 | 题解 | 标签 | 难度 |
|---|---|---|---|---|
| 0705 | 设计哈希集合 | Python | 哈希表 | 简单 |
| 0706 | 设计哈希映射 | Python | 哈希表 | 简单 |
| 0217 | 存在重复元素 | Python | 数组、哈希表 | 简单 |
| 0219 | 存在重复元素 II | Python | 数组、哈希表 | 简单 |
| 0220 | 存在重复元素 III | Python | 排序、有序集合、哈希表 | 中等 |
| 1941 | 检查是否所有字符出现次数相同 | Python | 哈希表、字符串、计数 | 简单 |
| 0136 | 只出现一次的数字 | Python | 位运算、数组 | 简单 |
| 0383 | 赎金信 | Python | 哈希表、字符串、计数 | 简单 |
| 0349 | 两个数组的交集 | Python | 数组、哈希表 | 简单 |
| 0350 | 两个数组的交集 II | Python | 数组、哈希表 | 简单 |
| 0036 | 有效的数独 | Python | 哈希表 | 中等 |
| 0001 | 两数之和 | Python | 数组、哈希表 | 简单 |
| 0015 | 三数之和 | Python | 数组、双指针 | 中等 |
| 0018 | 四数之和 | Python | 数组、哈希表、双指针 | 中等 |
| 0454 | 四数相加 II | Python | 哈希表 | 中等 |
| 0041 | 缺失的第一个正数 | Python | 数组、哈希表 | 困难 |
| 0128 | 最长连续序列 | Python | 并查集、数组、哈希表 | 中等 |
| 0202 | 快乐数 | Python | 哈希表、数学 | 简单 |
| 0242 | 有效的字母异位词 | Python | 字符串、哈希表、排序 | 简单 |
| 0205 | 同构字符串 | Python | 哈希表 | 简单 |
| 0442 | 数组中重复的数据 | |||
| 剑指 Offer 61 | 扑克牌中的顺子 | Python | 数组、排序 | 简单 |
| 0268 | 丢失的数字 | Python | 位运算、数组、数学 | 简单 |
| 剑指 Offer 03 | 数组中重复的数字 | Python | 数组、哈希表、排序 | 简单 |
| 0451 | 根据字符出现频率排序 | Python | 哈希表、字符串、桶排序、计数、排序、堆(优先队列) | 中等 |
| 0049 | 字母异位词分组 | Python | 字符串、哈希表 | 中等 |
| 0599 | 两个列表的最小索引总和 | Python | 哈希表 | 简单 |
| 0387 | 字符串中的第一个唯一字符 | Python | 字符串、哈希表 | 简单 |
| 0447 | 回旋镖的数量 | Python | 哈希表、数学 | 中等 |
| 0149 | 直线上最多的点数 | Python | 哈希表、数学 | 困难 |
| 0359 | 日志速率限制器 | Python | 设计、哈希表 | 简单 |
| 0811 | 子域名访问计数 | Python | 数组、哈希表、字符串、计数 | 中等 |
2.2 设计哈希集合 、设计哈希映射
要求不使用内建的哈希表库,自行实现一个哈希集合(HashSet),满足以下操作:
- void add(key) 向哈希集合中插入值 key 。
- bool contains(key) 返回哈希集合中是否存在这个值 key 。
- void remove(key) 将给定值 key 从哈希集合中删除。如果哈希集合中没有这个值,什么也不做。
示例:
#输入: |
思路:利用「数组+链表」的方式实现哈希集合
定义一个一维长度为 buckets 的二维数组 table。第一维度用于计算哈希函数,为 key 分桶。第二个维度用于寻找 key 存放的具体位置。第二维度的数组会根据 key 值动态增长,模拟真正的链表。
class MyHashSet: |
设计哈希映射和上一题其实是一样的,可以直接套用代码:
class MyHashMap: |
2.3 存在重复元素I、II、III
- 0217 存在重复元素
- 0219 存在重复元素 II
- 0220 存在重复元素 III
2.3.1 存在重复元素
给你一个整数数组 nums 。如果任一值在数组中出现 至少两次 ,返回 true ;如果数组中每个元素互不相同,返回 false
return False if len(nums)==len(set(nums)) else True |
2.3.2 存在重复元素 II
给你一个整数数组 nums 和一个整数 k ,判断数组中是否存在两个 不同的索引 i 和 j ,满足 nums[i] == nums[j] 且 abs(i - j) <= k 。如果存在,返回 true ;否则,返回 false 。
解法一:class Solution:
def containsNearbyDuplicate(self, nums: List[int], k: int) -> bool:
d=set()
for i in range(len(nums)):
if nums[i] in d:
return True
d.add(nums[i])
if len(d)>k:
d.remove(nums[i-k])
return False
解法二:class Solution:
def containsNearbyDuplicate(self, nums: List[int], k: int) -> bool:
d=dict()
# 如果k值超过数组长度,将其赋值为数组长度-1,然后统计前k个数字的出现此数。
# 如果某个元素已经出现在字典中,直接返回True
if k>len(nums)-1:
k=len(nums)-1
l,r=0,k
for i in range(k+1):
if nums[i] not in d:
d[nums[i]]=d.get(nums[i],0)+1
else:
return True
# 依次往右滑动窗口,每次删除左边界元素,加入右边界元素(次数+1)
while r<len(nums)-1:
l+=1
r+=1
del d[nums[l-1]]
if nums[r] not in d:
d[nums[r]]=d.get(nums[r],0)+1
else:
return True
return False
2.3.3 存在重复元素 III
给你一个整数数组 nums 和两个整数 k 和 t 。请你判断是否存在 两个不同下标 i 和 j,使得 abs(nums[i] - nums[j]) <= t ,同时又满足 abs(i - j) <= k 。
思路 1:滑动窗口(固定长度)
- 使用一个长度为
k,右指针为i的滑动窗口,每次遍历到nums[i]时,只需要检查前k个元素是否有某个元素在[nums[i] - t, nums[i + t]区间内即可。 - 检查
k个元素是否在[nums[i] - t, nums[i + t]区间,可以借助有序数组(比如SortedList)+ 二分查找来解决,从而减少时间复杂度。如果是无序数组,则滑动窗口内只能对于每个元素都遍历一次队列来检查是否有元素符合条件。如果数组的长度为
n,则使用队列的时间复杂度为O(nk),会超出时间限制。
具体步骤如下:
- 使用有序数组类
window维护一个长度为k的窗口,满足数组内元素有序,且支持增加和删除操作。 - 将当前元素填入窗口中,即
window.add(nums[i])。 - 当窗口元素大于
k个时,移除窗口最左侧元素。 当窗口元素小于等于
k个时(即i<k时窗口才移动,不到k个元素,后面固定有k个元素):- 使用二分查找算法
windows.bisect_left,查找nums[i]在window中的位置idx(windows是有序数组,每次遍历的元素nums[i]会放到窗口中的合适位置)。 - 判断
window[idx]与相邻位置上元素差值绝对值,若果满足abs(window[idx] - window[idx - 1]) <= t或者abs(window[idx + 1] - window[idx]) <= t时返回True。
- 使用二分查找算法
重复
2~4步,直到遍历至数组末尾,如果还没找到满足条件的情况,则返回False。
class Solution: |
- 时间复杂度:TreeSet 基于红黑树,查找和插入都是 O(logk) 复杂度。整体复杂度为 O(nlogk)
- 空间复杂度:O(k)
SortedList详情请参考《SortedList【python类】》
思路 2:桶排序
述解法无法做到线性的原因是:我们需要在大小为 k 的滑动窗口所在的「有序集合」中找到与 nums[i] 接近的数。如果我们能够将 k 个数字分到 k 个桶的话,那么我们就能 在O(1) 的复杂度确定是否有 [nums[i]−t,nums[i]+t] 的数字(检查目标桶是否有元素)。
- 利用桶排序的思想,将桶的大小设置为
t + 1。只需要使用一重循环遍历位置i,然后根据nums[i] // (t + 1),从而决定将nums[i]放入哪个桶中。 - 这样在同一个桶内各个元素之间的差值绝对值都小于等于
t。而相邻桶之间的元素,只需要校验一下两个桶之间的差值是否不超过t。这样就可以以 $O(1)$ 的时间复杂度检测相邻2 * k个元素是否满足abs(nums[i] - nums[j]) <= t。 - 而
abs(i - j) <= k条件则可以通过在一重循环遍历时,将超出范围的nums[i - k]从对应桶中删除,从而保证桶中元素一定满足abs(i - j) <= k。
具体步骤如下:
- 将每个桶的大小设置为
t + 1。我们将元素按照大小依次放入不同的桶中。 - 遍历数组
nums中的元素,对于元素nums[i]:- 如果
nums[i]放入桶之前桶里已经有元素了,那么这两个元素必然满足abs(nums[i] - nums[j]) <= t, - 如果之前桶里没有元素,那么就将
nums[i]放入对应桶中。 - 再判断左右桶的左右两侧桶中是否有元素满足
abs(nums[i] - nums[j]) <= t。 - 然后将
nums[i - k]之前的桶清空,因为这些桶中的元素与nums[i]已经不满足abs(i - j) <= k了。
- 如果
- 最后上述满足条件的情况就返回
True,最终遍历完仍不满足条件就返回False。class Solution:
def containsNearbyAlmostDuplicate(self, nums: List[int], k: int, t: int) -> bool:
bucket_dict = dict()
for i in range(len(nums)):
# 将 nums[i] 划分到大小为 t + 1 的不同桶中
num = nums[i] // (t + 1)
# 桶中已经有元素了
if num in bucket_dict:
return True
# 把 nums[i] 放入桶中
bucket_dict[num] = nums[i]
# 判断左侧桶是否满足条件
if (num - 1) in bucket_dict and abs(bucket_dict[num - 1] - nums[i]) <= t:
return True
# 判断右侧桶是否满足条件
if (num + 1) in bucket_dict and abs(bucket_dict[num + 1] - nums[i]) <= t:
return True
# 将 i-k 之前的旧桶清除,因为之前的桶已经不满足条件了
if i >= k:
bucket_dict.pop(nums[i-k] // (t + 1))
return False2.4 只出现一次的数字
给你一个 非空 整数数组 nums ,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。你必须设计并实现线性时间复杂度的算法来解决此问题,且该算法只使用常量额外空间。
如果没有时间复杂度和空间复杂度的限制,可以使用哈希表 / 集合来存储每个元素出现的次数,如果哈希表中没有该数字,则将该数字加入集合,如果集合中有了该数字,则从集合中删除该数字,最终成对的数字都被删除了,只剩下单次出现的元素。
但是题目要求不使用额外的存储空间,就需要用到位运算中的异或运算。
异或运算 $\oplus$ 的三个性质:
- 任何数和 $0$ 做异或运算,结果仍然是原来的数,即 $a \oplus 0 = a$。
- 数和其自身做异或运算,结果是 $0$,即 $a \oplus a = 0$。
- 异或运算满足交换率和结合律:$a \oplus b \oplus a = b \oplus a \oplus a = b \oplus (a \oplus a) = b \oplus 0 = b$。
根据异或运算的性质,对 $n$ 个数不断进行异或操作,最终可得到单次出现的元素。
class Solution(object): |
2.5 有效的数独
请你判断一个 9 x 9 的数独是否有效。
输入:board = |

思路一:哈希表
判断数独是否有效,需要分别看每一行、每一列、每一个 3 * 3 的小方格是否出现了重复数字,如果都没有出现重复数字就是一个有效的数独,如果出现了重复数字则不是有效的数独。
- 用
3个9 * 9的数组分别来表示该数字是否在所在的行,所在的列,所在的方格出现过。其中方格角标的计算用box[(i / 3) * 3 + (j / 3)][n]来表示。 - 双重循环遍历数独矩阵。如果对应位置上的数字如果已经在在所在的行 / 列 / 方格出现过,则返回
False。 - 遍历完没有重复出现,则返回
Ture。
- 九宫格1-3坐标:(0-2,0-2),(0-2,3-5),(0-2,6-8)
- 九宫格4-6坐标:(3-5,0-2),(3-5,3-5),(3-5,6-8)
- 九宫格7-9坐标:(6-8,0-2),(6-8,3-5),(6-8,6-8)
- 所以每个元素属于第几个九宫格,是
i//3的三倍+j//3思路二:列表查找
def isValidSudoku(self, board):
"""
:type board: List[List[str]]
:rtype: bool
"""
row=[dict() for _ in range(9)] # 创建一个包含9个字典的列表,其中每个字典统计每一行元素出现的次数
col=[dict() for _ in range(9)] # 统计每一列元素出现的次数
box=[dict() for _ in range(9)] # 统计每个九宫格元素出现的次数
for i in range(9):
for j in range(9):
if board[i][j]=='.':
continue
num=int(board[i][j])
idx=(i//3)*3+j//3
# 查找各行、各列、各九宫格中,是否出现过num这个元素。没有出现就返回0
a,b,c=row[i].get(num,0),col[j].get(num,0),box[idx].get(num,0)
if a!=0 or b!=0 or c!=0:
return False
# 在各行、列、九宫格中,将出现的数字次数计为1
row[i][num]=1
col[j][num]=1
box[idx][num]=1
return True
class Solution(object): |
2.6 两数之和、三数之和、四数之和、四数相加
- 0001. 两数之和
- 0015. 三数之和
- 0018. 四数之和
- 0454. 四数相加 II
2.6.1 两数之和
给定一个整数数组nums和一个整数目标值target,请你在该数组中找出 和为target的那 两个 整数,并返回它们的数组下标(任意顺序)。- 输入:nums = [2,7,11,15], target = 9
- 输出:[0,1]
- 解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
class Solution(object): |
2.6.2 三数之和
思路 1:对撞指针
直接三重遍历查找 a、b、c 的时间复杂度是:$O(n^3)$。我们可以通过一些操作来降低复杂度。
先将数组进行排序,再使用对撞指针</font >,从而保证所找到的三个元素是不重复的,且使用双指针减少一重遍历。时间复杂度为:$O(nlogn)$。
第一重循环遍历 i,对于每个 nums[i] 元素,从 i 元素的下一个位置开始,使用对撞指针 left,right。left 指向 i 的下一个位置,right 指向末尾位置。先将 left 右移、right 左移去除重复元素,再进行下边的判断。
- 如果
nums[a] + nums[left] + nums[right] = 0,则得到一个解,将其加入答案数组中,并继续将left右移,right左移; - 如果
nums[a] + nums[left] + nums[right] > 0,说明nums[right]值太大,将right向左移; - 如果
nums[a] + nums[left] + nums[right] < 0,说明nums[left]值太小,将left右移。
class Solution(object): |
2.6.3 四数之和
给你一个由 n 个整数组成的数组 nums ,和一个目标值 target 。请你找出并返回满足下述全部条件且不重复的四元组 [nums[a], nums[b], nums[c], nums[d]] (若两个四元组元素一一对应,则认为两个四元组重复):
- 0 <= a, b, c, d < n
- a、b、c 和 d 互不相同
- nums[a] + nums[b] + nums[c] + nums[d] == target
- 你可以按 任意顺序 返回答案 。
- 示例:
输入:nums = [1,0,-1,0,-2,2], target = 0 |
基本上就是套用三数之和的思路,也使用排序数组和对撞指针,去除一次循环遍历。class Solution(object):
def fourSum(self, nums, target):
"""
:type nums: List[int]
:type target: int
:rtype: List[List[int]]
"""
nums.sort()
le=len(nums)
ans=[]
for a in range(le):
#if nums[a]>target:
# break
# 这里和三数之和不一样。三数之和nums[i]>0,所有都是正数不用计算了。这里第一个数>target,还可以有负数使和变得更小
if a>0 and nums[a]==nums[a-1]:
continue
for b in range(a+1,le):
if b>a+1 and nums[b]==nums[b-1]:
continue
left,right=b+1,le-1
while left<right:
if nums[a]+nums[b]+nums[left]+nums[right]>target:
right-=1
elif nums[a]+nums[b]+nums[left]+nums[right]<target:
left+=1
else:
ans.append([nums[a],nums[b],nums[left],nums[right]])
while left<right and nums[left]==nums[left+1]:left+=1
while left<right and nums[right]==nums[right-1]:right-=1
left+=1
right-=1
return ans
2.6.4 四数相加
直接暴力搜索的时间复杂度是 $O(n^4)$。我们可以降低一下复杂度。将四个数组分为两组。nums1 和 nums2 分为一组,nums3 和 nums4 分为一组。
已知 $nums1[i] + nums2[j] + nums3[k] + nums4[l] = 0$,可以得到 $nums1[i] + nums2[j] = -(nums3[k] + nums4[l])$
建立一个哈希表。两重循环遍历数组 nums1、nums2,先将 $nums[i] + nums[j]$ 的和记录到哈希表中,然后再用两重循环遍历数组 nums3、nums4。如果 $-(nums3[k] + nums4[l])$ 的结果出现在哈希表中,则将结果数累加到答案中。最终输出累加之后的答案。
class Solution(object): |
2.7 缺失的第一个正数
给你一个未排序的整数数组 nums ,请你找出其中没有出现的最小的正整数。请你实现时间复杂度为 O(n) 并且只使用常数级别额外空间的解决方案。
输入:nums = [1,2,0] |
如果本题没有额外的时空复杂度要求,那么就很容易实现:
我们可以将数组所有的数放入哈希表,随后从 1 开始依次枚举正整数,并判断其是否在哈希表中。这种解法时空复杂度都是
O(n);我们可以从 1 开始依次枚举正整数,并遍历数组,判断其是否在数组中。这种解法时间复杂度$O(n^2)$,空间复杂度
O(1)
所以可以考虑利用给定数组中的空间来存储一些状态。即:如果题目给定的数组是不可修改的,那么就不存在满足时空复杂度要求的算法;但如果我们可以修改给定的数组,那么是存在满足要求的算法的。
思路 1:原地哈希
我们可以将当前数组视为哈希表。一个长度为 n 的数组,对应存储的元素值应该为 [1, n + 1] 之间,其中还包含一个缺失的元素。
- 遍历当前数组,将当前元素放到其对应位置上(比如元素值为
1的元素放到数组第0个位置上、元素值为2的元素放到数组第1个位置上,等等)。- 对于遍历到的数 $x=nums[i]$,如果 $x∈[1,N]$,我们就知道 $x$ 应当出现在数组中的 $x−1$ 的位置(下标从0开始),因此交换 $nums[i]$ 和 $nums[x−1]$,这样 $x$ 就出现在了正确的位置。在完成交换后,新的 $nums[i]$ 可能还在 $[1,N]$ 的范围内,我们需要继续进行交换操作,直到 $x\notin [1,N]$。
- 上面的方法可能会陷入死循环。如果 $nums[i] == nums[x−1]$ ,那么就会无限交换下去。此时$x$ 已经出现在了正确的位置。因此我们可以跳出循环,开始遍历下一个数。
- 然后再次遍历一遍数组。遇到第一个元素值不等于下标 + 1 的元素,就是答案要求的缺失的第一个正数。
- 如果遍历完没有在数组中找到缺失的第一个正数,则缺失的第一个正数是
n + 1。
class Solution: |
2.8 最长连续序列
思路一:排序+滑动窗口,时间复杂度是 $O(nlogn)$class Solution(object):
def longestConsecutive(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
if len(nums)==0:
return 0
else:
nums=list(set(nums)) # 去除重复元素
nums.sort()
left,right=0,1
ans=1 # 默认起始的连续序列长度为1(只有一个元素时)
# 如果差值不为1,左右指针右移;否则差值为1,右指针不停右移,同时记录连续序列的长度
while left<right and right<len(nums):
if nums[right]!=nums[left]+1:
left+=1
right+=1
else:
while right<len(nums) and nums[right]==nums[right-1]+1:
ans=max(ans,right-left+1)
right+=1
# 右移到差值不为1时右指针停止移动,left跳到right前一个位置
left=right-1
return ans
思路二:哈希表
- 先 将数组存储到集合中进行去重,然后使用
curr_streak维护当前连续序列长度,使用ans维护最长连续序列长度。 - 遍历集合中的元素,对每个元素进行判断,如果该元素不是序列的开始(即
num - 1在集合中),则跳过。 - 如果
num - 1不在集合中,说明num是序列的开始,判断num + 1、nums + 2、...是否在哈希表中,并不断更新当前连续序列长度curr_streak。并在遍历结束之后更新最长序列的长度。 - 最后输出最长序列长度。
class Solution(object): |
2.9 根据字符出现频率排序
给定一个字符串 s ,根据字符出现的 频率 对其进行 降序排序 。一个字符出现的 频率 是它出现在字符串中的次数。返回 已排序的字符串 。如果有多个答案,返回其中任何一个。
输入: s = "tree" |
class Solution(object): |
2.10 字母异位词分组
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。字母异位词 是由重新排列源单词的字母得到的一个新单词,所有源单词中的字母通常恰好只用一次。
输入: strs = ["eat", "tea", "tan", "ate", "nat", "bat"] |
解题思路:
对每一个字符串先进行排序,然后使用哈希表记录字母相同的子字符串。(排序后结果一样的子串,存储在一个列表里)
最终将哈希表的值转换为对应数组返回结果。
class Solution(object):
def groupAnagrams(self, strs):
"""
:type strs: List[str]
:rtype: List[List[str]]
"""
d=dict()
for ch in strs:
# 子串进行字母排序,sorted的结果是一个列表,str将其转为字符串
sort_ch=str(sorted(ch))
if sort_ch not in d:
d[sort_ch]=[ch]
else:
d[sort_ch]+=[ch]
ans=[]
for k,v in d.items():
ans+=[v]
return ans2.11 两个列表的最小索引总和
假设 Andy 和 Doris 想在晚餐时选择一家餐厅,并且他们都有一个表示最喜爱餐厅的列表,每个餐厅的名字用字符串表示。
你需要帮助他们用最少的索引和找出他们共同喜爱的餐厅。 如果答案不止一个,则输出所有答案并且不考虑顺序。 你可以假设答案总是存在。
输入:list1 = ["Shogun", "Tapioca Express", "Burger King", "KFC"],list2 = ["KFC", "Shogun", "Burger King"] |
思路1
遍历
list1,建立一个哈希表d1,以list1[i] : i键值对的方式,将list1的下标存储起来。遍历
list2,判断list2[i]是否在哈希表中,如果在,则根据i + list1_dict[i]和min_sum的比较,判断是否需要更新最小索引和。- 如果
i + list1_dict[i] < min_sum,则更新最小索引和,并清空答案数据,添加新的答案; - 如果
i + list1_dict[i] == min_sum,则更新最小索引和,并添加答案。
- 如果
class Solution: |
思路2:
- 遍历
list1,建立一个哈希表d1,以list1[i] : i键值对的方式,将list1的下标存储起来。 - 遍历
list2,如果list2[j]在哈希表中,将这个字符和其在两个列表中的下标和分别存储在列表ls和res中 - 最终遍历
res,当遍历到最小下标和时,将ls对应位置的字符取出,存到最终结果中
class Solution(object): |
2.12 字符串中的第一个唯一字符
给定一个字符串 s ,找到 它的第一个不重复的字符,并返回它的索引 。如果不存在,则返回 -1 。
输入: s = "leetcode" |
class Solution(object): |
2.13 直线上最多的点数
给你一个数组 points ,其中 points[i] = [xi, yi] 表示 X-Y 平面上的一个点。求最多有多少个点在同一条直线上。
输入:points = [[1,1],[3,2],[5,3],[4,1],[2,3],[1,4]] |
解题思路
两个点可以确定一条直线,固定其中一个点,求其他点与该点的斜率,斜率相同的点则在同一条直线上。可以考虑把斜率当做哈希表的键值,存储经过该点,不同斜率的直线上经过的点数目。
对于点 i,查找经过该点的直线只需要考虑 (i+1,n-1) 位置上的点即可,因为 i-1 之前的点已经在遍历点 i-2 的时候考虑过了。
斜率的计算公式为 $\frac{dy}{dx} = \frac{y_j - y_i}{x_j - x_i}$。因为斜率是小数会有精度误差,所以我们考虑使用 (dx, dy) 的元组作为哈希表的 key。
注意: 需要处理倍数关系,dy、dx 异号情况,以及处理垂直直线(两点横坐标差为 0)的水平直线(两点横坐标差为 0)的情况。

class Solution: |
2.14 子域名访问计数
网站域名 “discuss.leetcode.com” 由多个子域名组成。顶级域名为 “com” ,二级域名为 “leetcode.com” ,最低一级为 “discuss.leetcode.com” 。当访问域名 “discuss.leetcode.com” 时,同时也会隐式访问其父域名 “leetcode.com” 以及 “com” 。
计数配对域名 是遵循 “rep d1.d2.d3” 或 “rep d1.d2” 格式的一个域名表示,其中 rep 表示访问域名的次数,d1.d2.d3 为域名本身。例如,”9001 discuss.leetcode.com” 就是一个 计数配对域名 ,表示 discuss.leetcode.com 被访问了 9001 次。
给你一个 计数配对域名 组成的数组 cpdomains ,解析得到输入中每个子域名对应的 计数配对域名 ,并以数组形式返回。可以按 任意顺序 返回答案。
输入:cpdomains = ["900 google.mail.com", "50 yahoo.com", "1 intel.mail.com", "5 wiki.org"] |
解题思路
这道题求解的是不同层级的域名的次数汇总,很容易想到使用哈希表。我们可以使用哈希表来统计不同层级的域名访问次数。具体做如下:
- 如果数组
cpdomains为空,直接返回空数组。 - 使用哈希表
times_dict存储不同层级的域名访问次数。 - 遍历数组
cpdomains。对于每一个计算机配对域名cpdomain:- 先将计算机配对域名的访问次数
times和域名domain进行分割。 - 然后将域名转为子域名数组
domain_list,逆序拼接不同等级的子域名sub_domain。 - 如果子域名
sub_domain没有出现在哈希表times_dict中,则在哈希表中存入sub_domain和访问次数times的键值对。 - 如果子域名
sub_domain曾经出现在哈希表times_dict中,则在哈希表对应位置加上times。
- 先将计算机配对域名的访问次数
- 遍历完之后,遍历哈希表
times_dict,将所有域名和访问次数拼接为字符串,存入答案数组中。 - 最后返回答案数组。
class Solution: |