
@[toc]
一、二叉堆和优先队列
队列有一种变体称为优先队列Priority Queue。优先队列的出队跟队列一样从队首出队,但在优先队列内部,数据项的次序却是由“优先级”来确定:
- 高优先级的数据项排在队首,而低优先级的数据项排在后面。
- 这样,优先队列的入队操作就比较复杂,需要将数据项根据其优先级尽量挤到队列前方。
1.1
实现优先队列的经典方案是采用二叉堆数据结构,二叉堆能够将优先队列的入队和出队复杂度都保持在$O(logn)$。Binary Heap库实现优先队列- 二叉堆逻辑结构上像二叉树,却是用非嵌套的列表来实现的。
- 最小key排在队首的称为最小堆
min heap(优先级最高);反之,最大key排在队首的是最大堆max heap。后续主要讲最小堆。如果用有序表来实现,入队时根据优先级插入到相应的位置,那么入队一定是$O(n)$的。队首出队复杂度是$O(n)$,队尾出队复杂度是$O(1)$
最小堆ADT BinaryHeap的操作定义如下:
BinaryHeap():创建一个空二叉堆对象;insert(k):将新key 加入到堆中(在合适的位置插入);findMin():返回堆中的最小项,最小项仍保留在堆中;delMin():返回堆中的最小项,同时从堆中删除;isEmpty():返回堆是否为空;size():返回堆中key 的个数;buildHeap(list):从一个key 列表创建新堆。
from pythonds.trees.binheap import BinHeap |
3 |
1.2 Python heapq库实现优先队列
Python heapq库的用法介绍:
heapq.heapify(list):从列表创建最小堆heapq._heapify_max(list):从列表创建最大堆heappush(heap, item):将数据item入堆heappop(heap):将堆中最小元素出堆(最小的就是堆顶),最大元素出堆是_heappop_max(heap);heapq.heapreplace(heap.item):先操作heappop(heap),再操作heappush(heap,item)。heapq.heappushpop(list, item):先操作heappush(heap,item),再操作heappop(heap),和上一个函数相反。heapq.merge(*iterables):合并多个堆,例如a = [2, 4, 6],b = [1, 3, 5],c = heapq.merge(a, b)heapq.nlargest(n, iterable,[ key]):返回堆中的最大n个元素heapq.nsmallest(n, iterable,[ key]):返回堆中最小的n个元素heapq[0]:返回堆顶
array = [10, 17, 50, 7, 30, 24, 27, 45, 15, 5, 36, 21] |
import heapq |
1.3 手动实现最小堆
1.3.1 非嵌套列表实现完全二叉树
为了使堆操作能保持在对数水平上,就必须采用二叉树结构。同时如果要使操作始终保持在对数数量级上,就必须始终保持二叉树的平衡,树根左右子树拥有相同数量的节点,所以考虑采用完全二叉树的结构来近似实现平衡。
完全二叉树的叶子节点只能出现在最下面两层,每个内部节点都有两个子节点,最多只有一个内部节点例外。最下层的叶子节点连续集中在最左边的位置上,即不存在只有右子树的情况。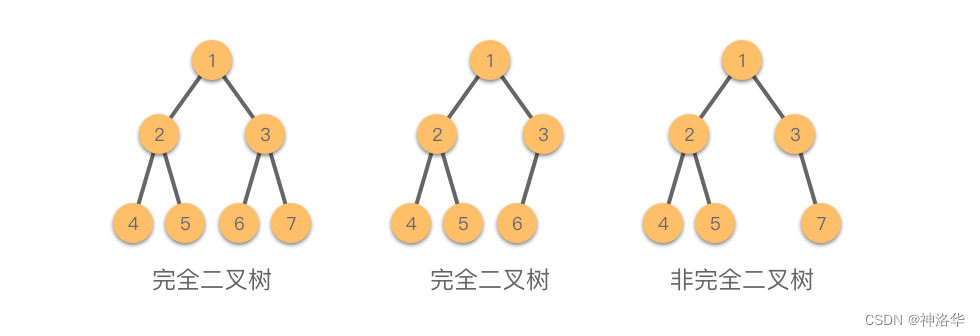
完全二叉树由于其特殊性,可以简单的用非嵌套列表方式实现,如下图:如果节点的下标为p,那么其左子节点下标为2p,右子节点为2p+1,其父节点下标为p//2。

1.3.2 非嵌套列表实现最小堆
上面讲过二叉堆分最小堆min heap和最大堆max heap:
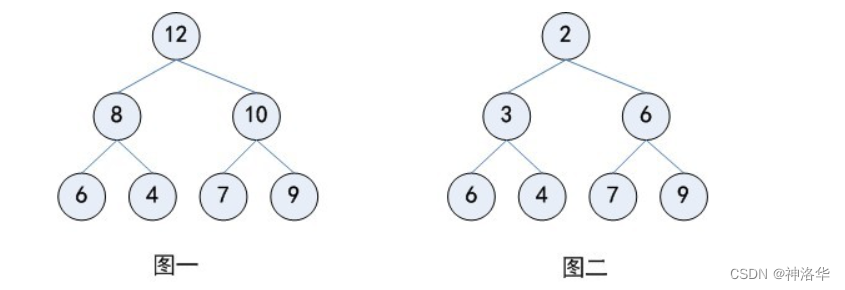
同样的,我们也可以用非嵌套列表实现最小堆:

在最小堆中,任何一条路径,均是一个已排序数列,根节点的
key最小。1.3.3 最小堆的python实现
之前讲到的完全二叉树节点下标规律是根节点从1开始才有用,如果从0开始就得做偏移,比较复杂。为了代码的简洁,我们建堆时,将下标为0的位置空出来不用,根节点从1开始。
- 二叉堆初始化:采用一个列表来保存堆数据,初始化下标0的位置,用一个0占位并一直保留,并初始化此时的
size=0。
class BinHeap: |
insert(key):将新key插入到堆中(上浮到正确位置)- 为了保持完全二叉树的性质,新key应该添加到列表末尾,但这样直接添加,显然无法保持堆次序。虽然对其它路径的次序没有影响,但可能破坏其到根的路径的次序。
- 将新key沿着路径“上浮”到其正确位置。新key的上浮不会影响其他路径节点的堆次序。
- 上浮是将新节点与其父节点比较,如果更大就将其和父节点进行交换


delMin():移走整个堆中最小的key,即根节点heapList[1]- 为了保持完全二叉树的性质,只用最后一个节点来代替根节点。同样,这操作还是破坏了堆次序。
- 将新的根节点沿着一条路径下沉,直到比两个子节点都小。
- 下沉的路径选择:如果比子节点大,那么选择较小的子节点交换下沉(保证交换后的根节点最小)。


buildHeap(lst)方法:从无序表直接生成堆,再用下沉法,能将总代价控制在$O(n)$。
用
insert(key)方法,将无序表的各个数据项insert到堆中,每一个的入堆操作都是$O(logn)$,n个元素,其复杂度就是$O(nlogn)$,用用下沉法,能将总代价控制在$O(n)$
代码实现:
# 二叉堆操作的实现 |
二、优先队列题目
| 题号 | 标题 | 题解 | 标签 | 难度 |
|---|---|---|---|---|
| 0703 | 数据流中的第 K 大元素 | Python | 树、设计、二叉搜索树、二叉树、数据流、堆(优先队列) | 简单 |
| 0347 | 前 K 个高频元素 | Python | 堆、哈希表 | 中等 |
| 0451 | 根据字符出现频率排序 | Python | 哈希表、字符串、桶排序、计数、排序、堆(优先队列) | 中等 |
| 0973 | 最接近原点的 K 个点 | Python | 几何、数组、数学、分治、快速选择、排序、堆(优先队列) | 中等 |
| 1296 | 划分数组为连续数字的集合 | Python | 贪心、数组、哈希表、排序 | 中等 |
| 0239 | 滑动窗口最大值 | Python | 队列,数组、滑动窗口、单调队列、堆(优先队列) | 困难 |
| 0295 | 数据流的中位数 | Python | 设计、双指针、数据流、排序、堆(优先队列) | 困难 |
| 0023 | 合并K个升序链表 | Python | 链表、分治、堆(优先队列)、归并排序 | 困难 |
| 0218 | 天际线问题 | Python | 树状数组、线段树、数组、分治、有序集合、扫描线、堆(优先队列) | 困难 |
2.1 数据流中第K大的元素
设计一个 KthLargest 类,用于找到数据流中第 k 大元素。
KthLargest(int k, int[] nums):使用整数 k 和整数流 nums 初始化对象。int add(int val):将 val 插入数据流 nums 后,返回当前数据流中第 k 大的元素。
输入: |
思路:使用最小堆保存前K个最大的元素,堆顶就是第k大的元素
- 建立大小为
k的最小堆,将前K个最大元素压入堆中。 - 每次
add操作时,将新元素压入堆中,如果堆中元素超出了k个,则将堆中最小元素(堆顶)移除,保证堆中元素保证不超过k个。 - 此时堆中最小元素(堆顶)就是整个数据流中的第
k大元素。
代码:class KthLargest(object):
import heapq
def __init__(self, k, nums):
"""
:type k: int
:type nums: List[int]
"""
self.k=k
self.queue=nums
heapq.heapify(self.queue)
print(self.queue)
def add(self, val):
"""
:type val: int
:rtype: int
"""
heapq.heappush(self.queue,val)
while len(self.queue)>self.k:
heapq.heappop(self.queue)
return self.queue[0]
2.2 最接近原点的 K 个点
给定一个由由平面上的点组成的列表
points,再给定一个整数K。要求找出K个距离原点(0, 0)最近的点。
- 这里的距离是平面上两点之间的距离,即欧几里德距离。
- 可以按任何顺序返回答案。除了点坐标的顺序之外,答案确保是唯一的(每个点的距离不一样)。
输入:points = [[1,3],[-2,2]], k = 1 |
思路:优先队列
- 使用列表
distance存储每个点到原点的距离 - 使用列表
ls存储每个点的距离,和其对应的点,即ls=list(zip(distance,points)) - 使用
heapq建立最小堆,堆顶元素永远是最小距离的点 - 遍历
k次,取出堆顶的点,存储到答案ans中class Solution:
def kClosest(self, points: List[List[int]], k: int) -> List[List[int]]:
distance=[(point[0]**2+point[1]**2)**0.5 for point in points]
ls=list(zip(distance,points))
# 根据距离建立最小堆
import heapq
heapq.heapify(ls)
ans=[]
count=0
while count<k:
ans.append(heapq.heappop(ls)[1])
count+=1
return ans2.3 前K个高频元素
给定一个整数数组 nums 和一个整数 k,返回出现频率前 k 高的元素。可以按任意顺序返回答案。
输入: nums = [1,1,1,2,2,3], k = 2 |
解法一:将元素根据其频次进行降序排列,前k个元素就是答案class Solution:
def topKFrequent(self, nums: List[int], k: int) -> List[int]:
from collections import Counter
d=dict(Counter(nums))
# 根据元素出现顺序降序排列,排序后d是一个元组列表[(key,value)]
d=sorted(d.items(),key=lambda x:x[1],reverse=True)
for i in range(k):
ans.append(d[i][0])
return ans
解法二:根据元素频次建立最大堆,遍历K次,将堆顶元素出栈保存
class Solution: |
2.4 滑动窗口最大值
给定一个整数数组 nums,再给定一个整数 k,表示为大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。我们只能看到滑动窗口内的 k 个数字,滑动窗口每次只能向右移动一位。
请返回滑动窗口中的最大值
输入:nums = [1,3,-1,-3,5,3,6,7], k = 3 |
思路 1:优先队列
我们可以使用优先队列(大顶堆)来存储长度为k的窗口内的数组,这样堆顶元素一定是滑动窗口内的最大值。
- 当堆顶元素还在窗口中,依旧返回堆顶元素。
- 当堆顶元素滑出了窗口,删除堆顶元素,直到堆顶元素还在窗口中,这时堆顶元素就是新的滑动窗口的最大值
假设窗口右指针为i,那么长度为k的滑动窗口左右指针就是[i-k+1,i]。当堆顶元素的索引<i-k+1时,表示堆顶元素不在滑动窗口中。以下是具体步骤:
- 初始的时候将前
k个元素加入优先队列的二叉堆中。存入优先队列的是数组值与索引构成的元组。优先队列将数组值作为优先级。 - 然后滑动窗口从第
k个元素开始遍历,将当前数组值和索引的元组插入到二叉堆中。 - 当二叉堆堆顶元素的索引已经不在滑动窗口的范围中时,即
q[0][1] <= i - k时,不断删除堆顶元素,直到最大值元素的索引在滑动窗口的范围中。 - 将最大值加入到答案数组中,继续向右滑动至遍历结束,返回答案
class Solution: |
2.5 寻找两个正序数组的中位数
给定两个正序(从小到大排序)数组 nums1、nums2,找出并返回这两个正序数组的中位数,并要求算法的时间复杂度应该为 $O(\log (m + n))$
输入:nums1 = [1,2], nums2 = [3,4] |
思路一:优先队列
假设两个数组连接后长度为n,那么此题等同于找到数组中第n//2+1大的数(n为奇数,n为偶数就是中间两个数的均值。所以可以考虑使用优先队列:
class Solution: |
2.6 数据流的中位数
设计一个支持一下两种操作的数组结构:
void addNum(int num):从数据流中添加一个整数到数据结构中。double findMedian():返回目前所有元素的中位数。
首先,我们可以使用两个优先队列(堆)来维护整个数据流数据:
- 大顶堆
self.maxq:存储小于中位数的数。 - 小顶堆
self.minq:存储大于中位数的数。
算法步骤:
- 初始化时,第一个元素先放入
self.maxq。这样当元素为奇数个时,总有self.maxq比self.minq多一个元素。 findMedian返回结果:- 当数据流元素数量为偶数:两个队列长度相等(
n1=n2),此时动态中位数为两者堆顶元素的平均值; - 当数据流元素数量为奇数:
n1=n2+1,此时动态中位数为self.maxq堆顶元素(小于中位数的数组中最大的那个)。
- 当数据流元素数量为偶数:两个队列长度相等(
addNum插入元素:- 当n1==0,当前元素直接插入大顶堆
self.maxq,因为heapq默认创建小顶堆,所以插入其负数,即heapq.heappush(self.maxq,-num) - 当n1==n2,说明插入前是偶数个元素,此时大顶堆
self.maxq应该多一个元素,但是分两种情况:num<-self.maxq[0],当前元素小于self.maxq中的最大值,所以直接入堆self.maxq(小于中位数的堆)num》-self.maxq[0],当前元素应该入小顶堆self.minq。但是为了保持self.maxq多一个元素,就需要再将self.minq中的最小值移到self.maxq中
- 当
n1!=n2,说明插入前是奇数个元素,此时应该是往小顶堆self.minq插入元素,也分两种情况:num>-self.maxq[0],当前元素小于self.maxq中的最大值,所以直接入堆self.minq(大于中位数的堆)num《-self.maxq[0],当前元素应该入大顶堆self.maxq。但是为了保持两堆元素个数相同,就需要再将self.maxq中的最大值移到self.minq中。
- 当n1==0,当前元素直接插入大顶堆
需要注意的是,heapq默认创建最小堆,为了达到创建并维护最大堆得效果:
- 所有入堆
self.maxq的元素应该加负号 - 从
self.maxq中移入self.minq的元素应该恢复符号(负负得正,heapq.heappush(self.minq,-temp)) - 比较
self.maxq堆顶元素时也要加负号,返回结果时也是也可以改写成(官方题解):class MedianFinder:
import heapq
def __init__(self):
self.maxq=[]
self.minq=[]
heapq.heapify(self.maxq) # 大顶堆,存储小于中位数的元素
heapq.heapify(self.minq) # 小顶堆,存储大于中位数的元素
def addNum(self, num: int) -> None:
n1,n2=len(self.maxq),len(self.minq)
# 当self.maxq为空,直接入大顶堆
if n1==0:
heapq.heappush(self.maxq,-num) # 取负数就是大顶堆效果
elif n1==n2:
if num<-self.maxq[0]: # 小于中位数直接入大顶堆
heapq.heappush(self.maxq,-num)
else: # 否则应该入小顶堆,但是得将小顶堆最小元素入大顶堆
heapq.heappush(self.minq,num)
temp=heapq.heappop(self.minq)
heapq.heappush(self.maxq,-temp)
else: # 当前元素是偶数个,需要入小顶堆
if num>-self.maxq[0]:
heapq.heappush(self.minq,num)
else:
heapq.heappush(self.maxq,-num)
temp=heapq.heappop(self.maxq)
heapq.heappush(self.minq,-temp)
def findMedian(self) -> float:
temp=self.maxq[0]
return -temp if len(self.maxq)>len(self.minq) else (self.minq[0]-temp)/2 - self.maxq为空或者num < -self.maxq[0]时,当前元素应该入堆self.maxq。
- 如果之前两堆元素相等,那么是轮到self.maxq入堆,无需额外的操作。此时当前元素入堆后, len(self.maxq)=len(self.minq) + 1 ;
- 如果之前就有len(self.maxq)=len(self.minq) + 1 ,那么入堆后len(self.maxq)>len(self.minq) + 1,此时应该将self.maxq堆顶元素pop到self.minq中。
- num 》-self.maxq[0],当前元素应该入堆self.minq,同样是分两种情况:
- 如果之前len(self.maxq)=len(self.minq) + 1,那么确实轮到入堆self.minq,无需额外操作。入堆后两堆元素个数相等
- 如果入堆后两堆元素个数不等,此时应该将self.minq堆顶元素pop到self.maxq中。
class MedianFinder: |
三、 二叉堆排序
3.1 最大堆排序思想
堆排序(Heap sort)基本思想:借用「堆结构」所设计的排序算法。将数组转化为大顶堆,重复从大顶堆中取出数值最大的节点,并让剩余的堆结构继续维持大顶堆性质。
堆排序算法步骤
- 建立初始堆:将无序序列构造成第
1个大顶堆(初始堆),使得n个元素的最大值处于序列的第1个位置。 - 调整堆:交换序列的第
1个元素(最大值元素)与第n个元素的位置。将序列前n - 1个元素组成的子序列调整成一个新的大顶堆,使得n - 1个元素的最大值处于序列第1个位置,从而得到第2个最大值元素。 - 调整堆:交换子序列的第
1个元素(最大值元素)与第n - 1个元素的位置。将序列前n - 2个元素组成的子序列调整成一个新的大顶堆,使得n - 2个元素的最大值处于序列第1个位置,从而得到第3个最大值元素。 - 依次类推,不断交换子序列的第
1个元素(最大值元素)与当前子序列最后一个元素位置,并将其调整成新的大顶堆。直到子序列剩下一个元素时,排序结束。此时整个序列就变成了一个有序序列。
从堆排序算法步骤中可以看出:堆排序算法主要涉及「调整堆」和「建立初始堆」两个步骤。
3.2 调整最大堆
调整堆方法:把移走了最大值元素以后的剩余元素组成的序列再构造为一个新的堆积(前面讲的新key下沉)。具体步骤如下:
- 从根节点开始,自上而下地调整节点的位置,使其成为堆积。
- 判断序号为
i的节点与其左子树节点(序号为2 * i)、右子树节点(序号为2 * i + 1)中值关系。 - 如果序号为
i节点大于等于左右子节点值,则排序结束。 - 如果序号为
i节点小于左右子节点值,则将序号为i节点与左右子节点中值最大的节点交换位置。
- 判断序号为
- 因为交换了位置,使得当前节点的左右子树原有的堆积特性被破坏。于是,从当前节点的左右子树节点开始,自上而下继续进行类似的调整。
- 依次类推,直到整棵完全二叉树成为一个大顶堆。
调整堆方法演示
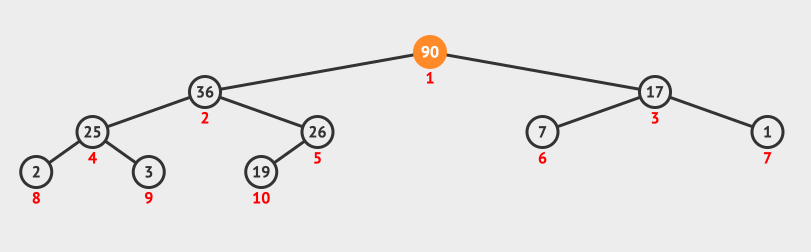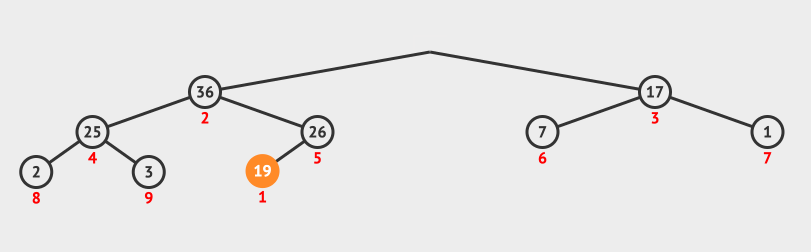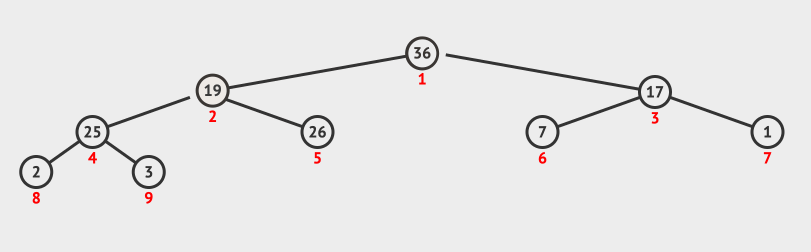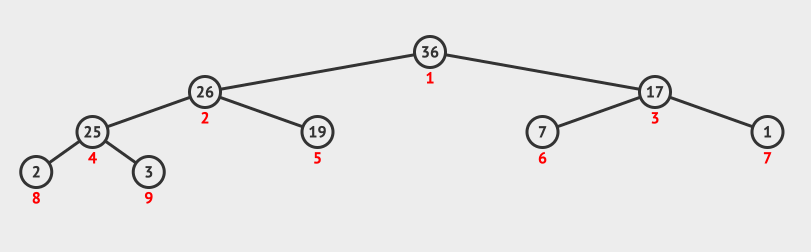
- 交换序列的第
1个元素90与最后1个元素19的位置,此时当前节点为根节点19。 - 判断根节点
19与其左右子节点值,因为17 < 19 < 36,所以将根节点19与左子节点36互换位置,此时当前节点为根节点19。 - 判断当前节点
36与其左右子节点值,因为19 < 25 < 26,所以将当前节点19与右节点26互换位置。调整堆结束。
3.3 建立初始堆
- 如果原始序列对应的完全二叉树(不一定是堆)的深度为
d,则从d - 1层最右侧分支节点(序号为 $\lfloor \frac{n}{2} \rfloor$)开始,初始时令 $i = \lfloor \frac{n}{2} \rfloor$,调用调整堆算法。 - 每调用一次调整堆算法,执行一次
i = i - 1,直到i == 1时,再调用一次,就把原始序列调整为了一个初始堆。
方法演示
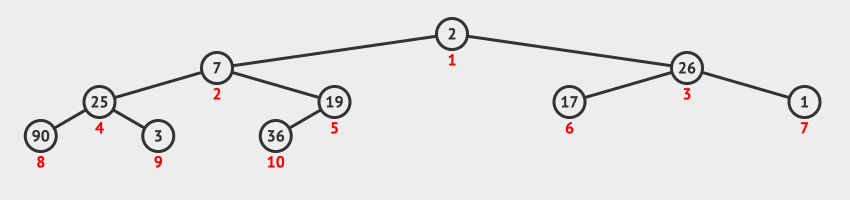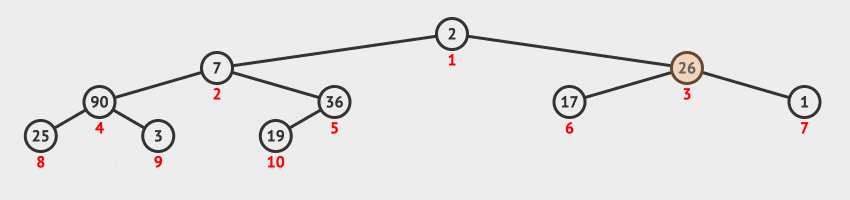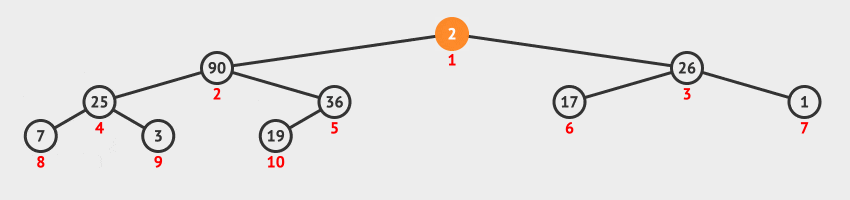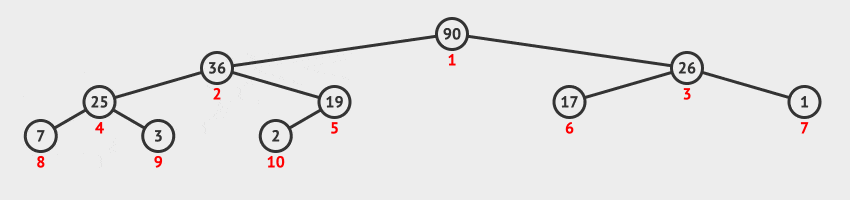
- 原始序列为
[2, 7, 26, 25, 19, 17, 1, 90, 3, 36],对应完全二叉树的深度为3。 - 从第
2层最右侧的分支节点,也就序号为5的节点开始,调用堆调整算法,使其与子树形成大顶堆。 - 节点序号减
1,对序号为4的节点,调用堆调整算法,使其与子树形成大顶堆。 - 节点序号减
1,对序号为3的节点,调用堆调整算法,使其与子树形成大顶堆。 - 节点序号减
1,对序号为2的节点,调用堆调整算法,使其与子树形成大顶堆。 - 节点序号减
1,对序号为1的节点,调用堆调整算法,使其与子树形成大顶堆。 - 此时整个原始序列对应的完全二叉树就成了一个大顶堆,建立初始堆完毕。
3.4 堆排序方法完整演示

- 原始序列为
[2, 7, 26, 25, 19, 17, 1, 90, 3, 36],先根据原始序列建立一个初始堆。 - 交换序列中第
1个元素(90)与第10个元素(2)的位置。将序列前9个元素组成的子序列调整成一个大顶堆,此时堆顶变为36。 - 交换序列中第
1个元素(36)与第9个元素(3)的位置。将序列前8个元素组成的子序列调整成一个大顶堆,此时堆顶变为26。 - 交换序列中第
1个元素(26)与第8个元素(2)的位置。将序列前7个元素组成的子序列调整成一个大顶堆,此时堆顶变为25。 - 以此类推,不断交换子序列的第
1个元素(最大值元素)与当前子序列最后一个元素位置,并将其调整成新的大顶堆。直到子序列只剩下最后一个元素1时,排序结束。此时整个序列变成了一个有序序列,即[1, 2, 3, 7, 17, 19, 25, 26, 36, 90]。
3.5 堆排序算法分析
- 时间复杂度:$O(n \times \log_2 n)$。
- 堆积排序的时间主要花费在两个方面:「建立初始堆」和「调整堆」。
- 设原始序列所对应的完全二叉树深度为 $d$,算法由两个独立的循环组成:
- 在第 $1$ 个循环构造初始堆积时,从 $i = d - 1$ 层开始,到 $i = 1$ 层为止,对每个分支节点都要调用一次调整堆算法,而一次调整堆算法,对于第 $i$ 层一个节点到第 $d$ 层上建立的子堆积,所有节点可能移动的最大距离为该子堆积根节点移动到最后一层(第 $d$ 层) 的距离,即 $d - i$。而第 $i$ 层上节点最多有 $2^{i-1}$ 个,所以每一次调用调整堆算法的最大移动距离为 $2^{i-1} * (d-i)$。因此,堆积排序算法的第 $1$ 个循环所需时间应该是各层上的节点数与该层上节点可移动的最大距离之积的总和,即:$\sum{i = d - 1}^1 2^{i-1} (d-i) = \sum{j = 1}^{d-1} 2^{d-j-1} \times j = \sum{j = 1}^{d-1} 2^{d-1} \times {j \over 2^j} \le n \sum{j = 1}^{d-1} {j \over 2^j} < 2n$。这一部分的时间花费为 $O(n)$。
- 在第 $2$ 个循环中,每次调用调整堆算法一次,节点移动的最大距离为这棵完全二叉树的深度 $d = \lfloor \log_2(n) \rfloor + 1$,一共调用了 $n - 1$ 次调整堆算法,所以,第 $2$ 个循环的时间花费为 $(n-1)(\lfloor \log_2 (n)\rfloor + 1) = O(n \times \log_2 n)$。
- 因此,堆积排序的时间复杂度为 $O(n \times \log_2 n)$。
- 空间复杂度:$O(1)$。由于在堆积排序中只需要一个记录大小的辅助空间,因此,堆积排序的空间复杂度为:$O(1)$。
- 排序稳定性:堆排序是一种 不稳定排序算法。
3.6 代码实现
class Solution: |
四、堆排序题目
4.1 数组中的第K个最大元素
给定整数数组 nums 和整数 k,请返回数组中第 k 个最大的元素,你必须设计并实现时间复杂度为 O(n) 的算法解决此问题。
- 堆排序
最小堆排序(本文1.3节代码)
class Solution(object): |
最大堆排序(本文第三章代码)
class Solution: |